AI4Bharat, a research lab at IIT Madras, is dedicated to advancing AI technology for Indian languages through open-source contributions. Over the past, the lab has developed and released a wide range of datasets, tools, and state-of-the-art models. The focus areas of the lab include transliteration, natural language understanding, generation, translation, automatic speech recognition, and speech synthesis. AI4Bharat’s work is recognized globally, with publications in top-tier conferences and deployments in real-world use cases, making a significant impact across academia, industry, and government sectors.

Cutting-edge work
across areas.
We are in the early stages of developing models and datasets for advancing Document Layout Parsing and OCR technologies to support the wide range of Indian scripts.
Coming Soon

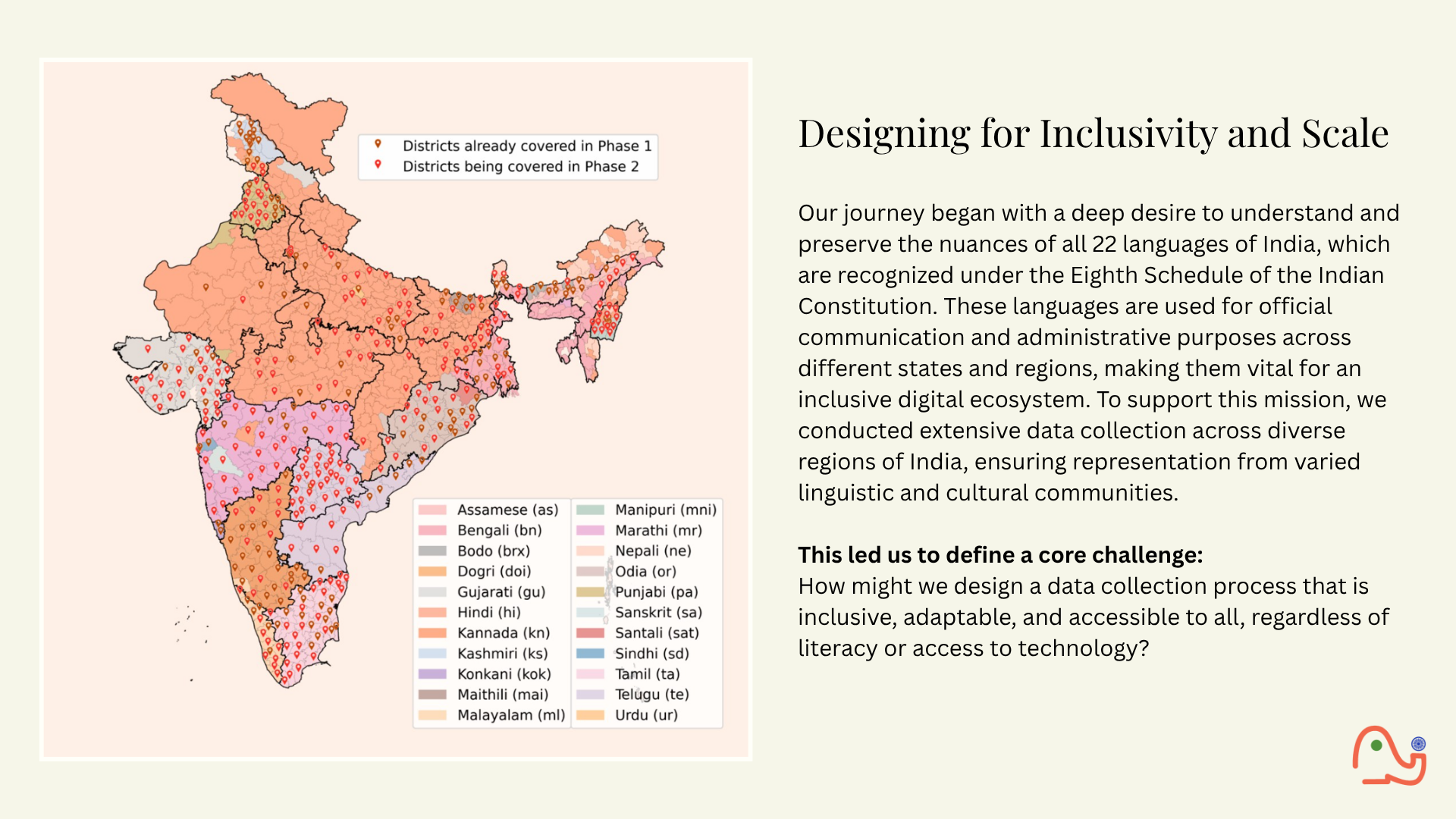
















Early on in our journey, we recognized that advancing Indian technology necessitates large-scale datasets. Thus, building and collecting extensive datasets across multiple verticals has become a critical endeavor at AI4Bharat. Thanks to generous grants from MeitY, we are spearheading pioneering efforts in data collection as part of the Data Management Unit of Bhashini. Our nationwide initiative aims to gather 15,000 hours of transcribed data from over 400 districts, encompassing all 22 scheduled languages of India. In parallel, our in-house team of over 100 translators is diligently creating a parallel corpus with 2.2 million translation pairs across 22 languages. To produce studio-quality data for expressive TTS systems, we have established recording studios in our lab, where professional voice artists contribute their expertise. Additionally, our annotators are meticulously labeling pages for Document Layout Parsing, accommodating the diverse scripts of India. To accelerate the development of Indic Large Language Models (LLMs), we are focused on building pipelines for curating and synthetically generating pre-training data, collecting contextually grounded prompts, and creating evaluation datasets that reflect India's rich linguistic tapestry. Collecting and annotating data at this scale demands standardization of processes and tools. To meet this challenge, AI4Bharat has invested in developing various open-source data collection and annotation tools, aiming to enhance these efforts not only within India but also in multilingual regions across the globe.






