Published on December 3, 2023 • 7 min read
By: Jay Gala, Pranjal A. Chitale, Raghavan AK, Varun Gumma, Sumanth Doddapaneni, Aswanth Kumar, Janki Nawale, Anupama Sujatha, Ratish Puduppully, Vivek Raghavan, Pratyush Kumar, Mitesh M. Khapra, Raj Dabre, Anoop Kunchukuttan

In May 2023, we released IndicTrans2 models, which were the first models to facilitate translations between all 22 scheduled Indic languages and English. This initiative aligns with our overarching vision to deliver open-source models of superior quality competitive with commercial systems. As a part of our endeavor, we strive to continually keep working on improving the accessibility and democratization of our models.
To this end, we first release Indic-Indic variants by repurposing pre-trained components of our English-centric models and light fine-tuning thereby offering a 50% reduction in inference time for Indic_Indic translation while being competitive to pivoting. Additionally, we release the distilled variants of all our models, thereby reducing the number of parameters by 5x, offering a 1.5x speed up, while maintaining competitive performance with the base models.
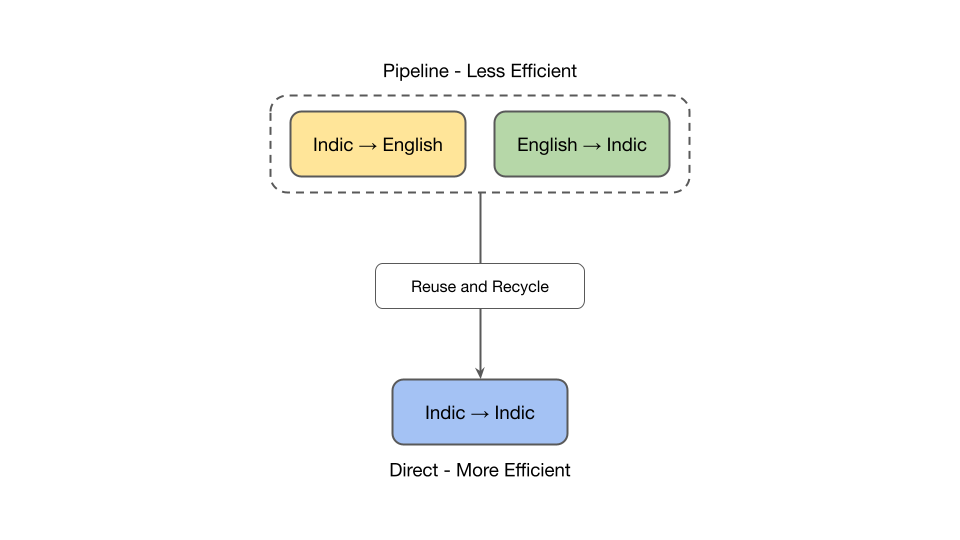
Our primary goal: Improve Indic-Indic translation efficiency. One of the limitations of our IndicTrans2 models released earlier was the requirement of a two-stage pipeline for Indic-Indic translation. In this process, the initial step involved translating the input text into English, followed by a subsequent stage of translation into the desired Indic language using the intermediate English translation. This two-step pipeline posed a practical limitation to the model's efficiency.
To address the aforementioned challenges and concerns, we release IndicTrans2-M2M, an Indic-Indic model that performs direct translations across 22 language script combinations. This model was adapted by repurposing the components of our pre-trained English-centric IndicTrans2 models with minimal fine-tuning. One salient highlight is that the Indic-Indic model, supporting 462 translation directions across the 22 scheduled Indic languages, exhibits competitive performance compared to the pivot baseline, thereby reducing the inference time by 50% and maintaining a comparable number of parameters to the English-centric models.
Our secondary goal: Practical and deployment-friendly compressed models. While our IndicTrans2 models demonstrate strong NMT performance and are relatively smaller compared to other models in terms of parameters, there might still be some challenges when it comes to deploying these models at scale as these might have high operational costs due to high GPU memory requirements. This limitation impedes the democratization of these models, particularly in scenarios characterized by low-infrastructure settings. Consequently, there is a need to explore strategies for constructing more compact models that can be deployed effectively in resource-constrained environments, while still maintaining translation quality.
To this end, we successfully distill our English-centric as well as Indic-Indic variants of IndicTrans2 models into more compact distilled versions, resulting in 200M parameters for English-centric and 320M parameters for Indic-Indic. Notably, these compact variants demonstrate competitive performance when compared to the teacher IndicTrans2 models with 1.2 billion parameters. Moreover, we release the distilled variants, which offer 1.5x throughput compared to teacher IndicTrans2 models. We believe that our contributions would be beneficial to the community and improve the accessibility of our models.
IndicTrans2 is the first open-source transformer-based multilingual NMT model that supports high-quality translations across all the 22 scheduled Indic languages — including multiple scripts for low-resource languages like Kashmiri, Manipuri, and Sindhi. It adopts script unification wherever feasible to leverage transfer learning by lexical sharing between languages. Overall, the model supports five scripts Perso-Arabic (Kashmiri, Sindhi, Urdu), Ol Chiki (Santali), Meitei (Manipuri), Latin (English), and Devanagari (used for all other languages).
Inference latency: Issue with this approach is that two models are required, so there is more overhead in terms of compute time.
Error propagation: The input to the second stage is the output of the first stage, so the biases of stage 1 will be further propagated to stage 2.
Nuances loss: Additionally, the use of an intermediate English pivot can result in a loss of nuances and subtleties in the original source language.
Data scarcity: Close to no data for low-resource pairs, particularly in the Indic-Indic setting
Data imbalance: Hindi-centric pairs are dominant, which may lead to poorer performance.
Compute heavy: In general, scales of Indic-Indic data are much lower, and might need to train with a combination of En-centric and Indic-Indic data, which is computationally expensive.
While the conventional method based on pivoting incurs additional inference processing, we employ the pre-trained encoder from the Indic-En model and the decoder from the En-Indic model to initialize IndicTrans2-M2M which is then fine-tuned. It is important to note that these two pre-trained components undergo independent training and lack synchronization, leading to an absence of zero-shot performance post-initialization. However, these pre-trained components serve as strong initialization to start with and can be further adapted with limited data (only high-quality BPCC-H Wiki data + synthetic data). Our method is inspired by works like XLM-T which repurpose the XLM via fine-tuning for machine translation.
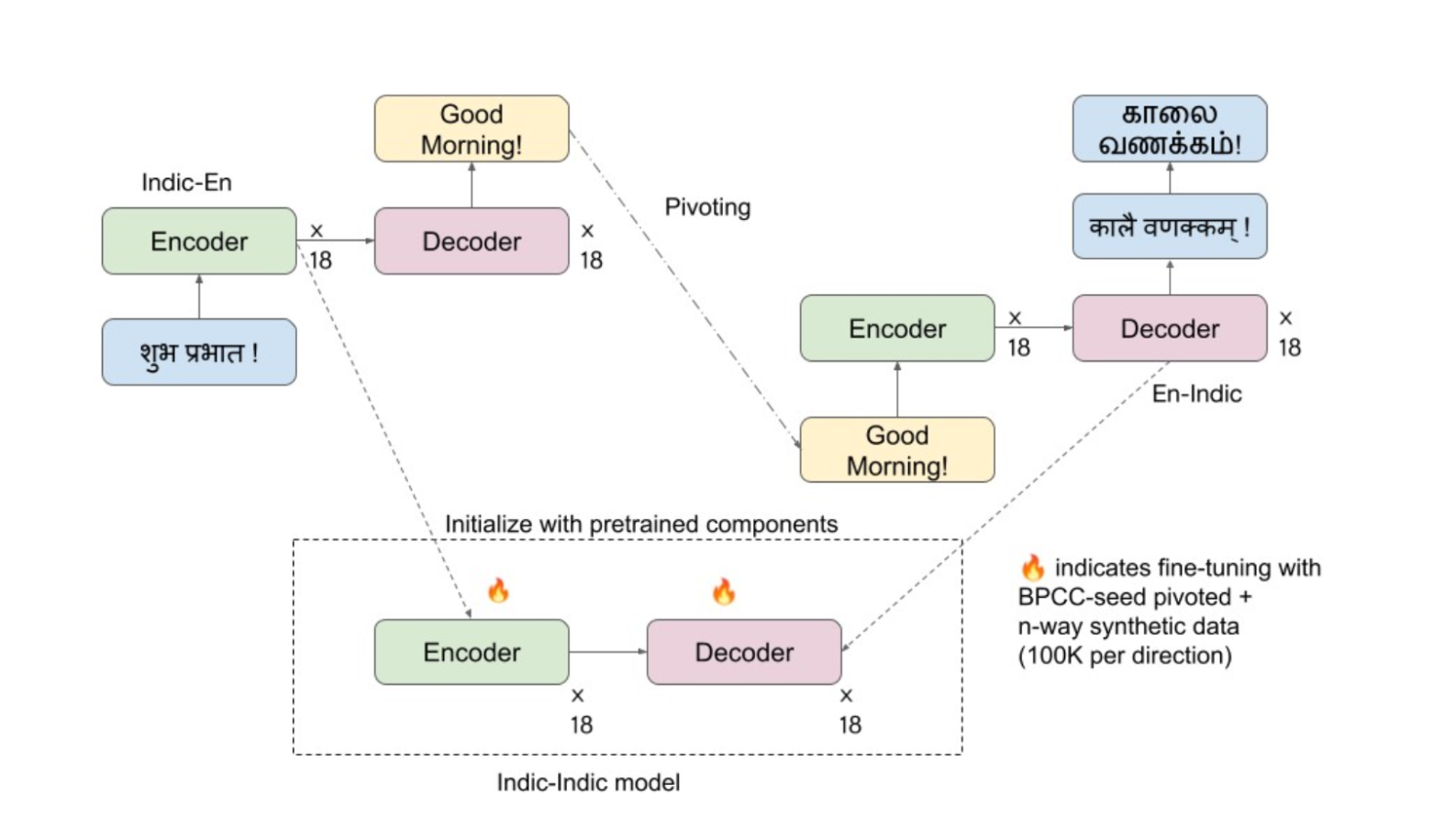
The BPCC-H Wiki, in its pivoted version, comprises 9.2 million entries spanning 462 pairs within the Indic-Indic linguistic domain.
A set of 100K synthetic bitext pairs was created for each translation direction, amounting to a total of 46.2 million pairs across the 462 Indic-Indic pairs. This synthetic data is augmented by selecting 100K English monolingual sentences from IndicCorpv2 (Doddapaneni et al., 2023) and utilizing the IndicTrans2 En-Indic model for translation across all 22 intended languages. Consequently, this process results in a n-way seed corpus with 100K sentences per direction across the 462 specified directions.
The aggregate data employed for fine-tuning encompasses 55.4 million pairs across all supported translation directions, accounting for the complete set of 462 directions.
It is important to note that the support for 462 Indic-Indic directions is achieved with a mere 25% of the data scales utilized in the training of IndicTrans2 auxiliary models, which in turn supported 25 English-centric directions.
As we leverage pre-trained components, even with limited Indic-Indic data, it is possible to obtain Indic-Indic performance competitive to model-based pivoting.
As various language teams independently translate BPCC-H Wiki the data scales across different pairs vary significantly, meaning that the data is not completely n-way in the current form. Therefore, for some pairs, the availability of data is extremely scarce.
Leveraging synthetic n-way seed data is a cheaper and compute-efficient way to obtain n-way parallel corpora, just by performing n inferences instead of nC2 inferences.
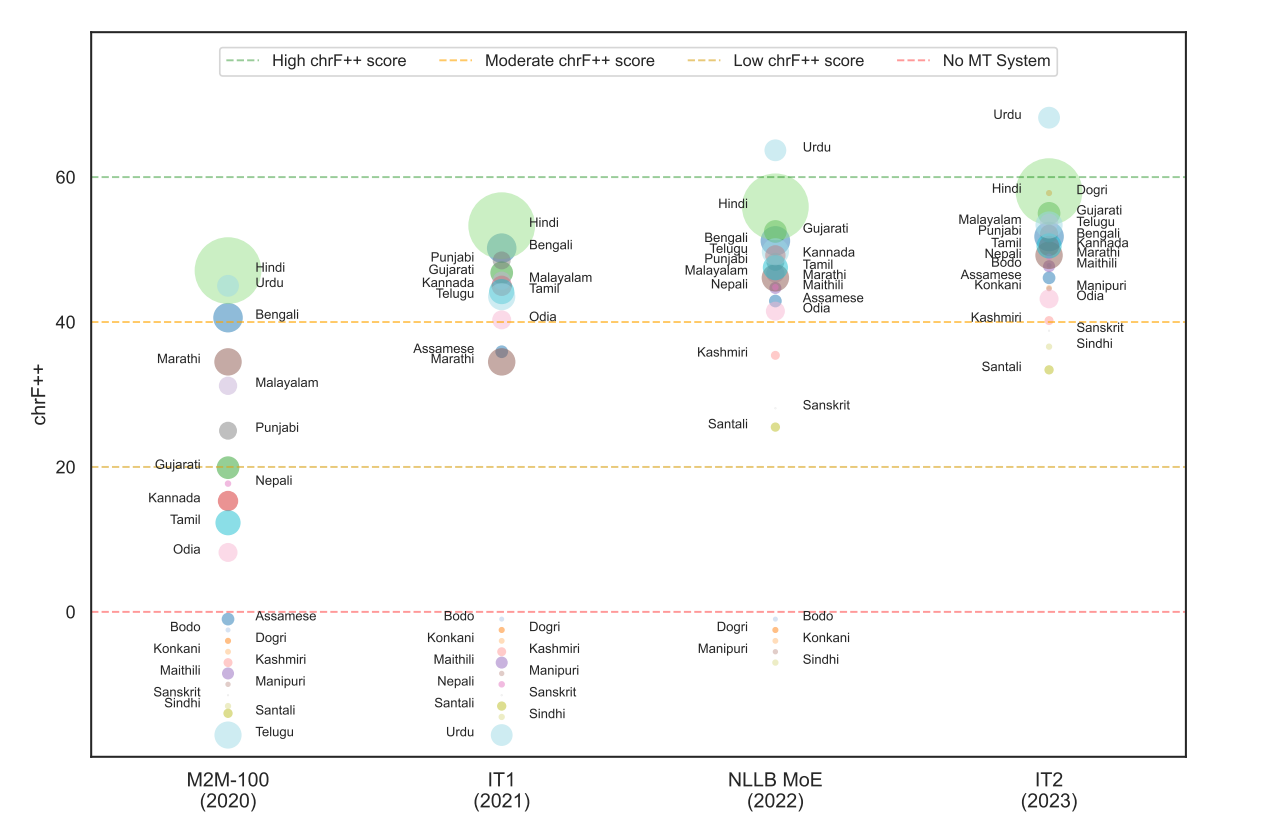
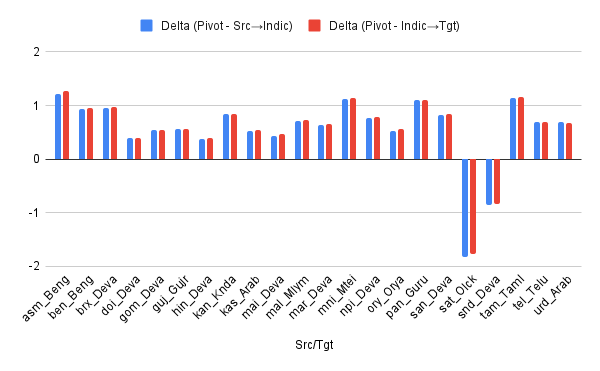
The figure below shows the gap between translation using our direct IndicTrans2-M2M model and translation using pivoting. IndicTrans2-M2M performs slightly worse, around 1 ChrF++ point, than the pivoted model, but is 2x faster. Additionally, we also observe performance gains in low-resource languages like Sindhi (Devanagari) and Santali.
Note that our Indic-Indic model is trained on data for all 462 (22 x 21) pairs and covers all 22 scheduled languages, but some script variants of languages like Kashmiri (Devanagari), Manipuri (Bengali) and Sindhi (Arabic) are not directly supported due to lack of training data for them.
Our English-centric IndicTrans2 models as well as our IndicTrans2-M2M model contain about 1.2 billion parameters, thereby making them slow to use.
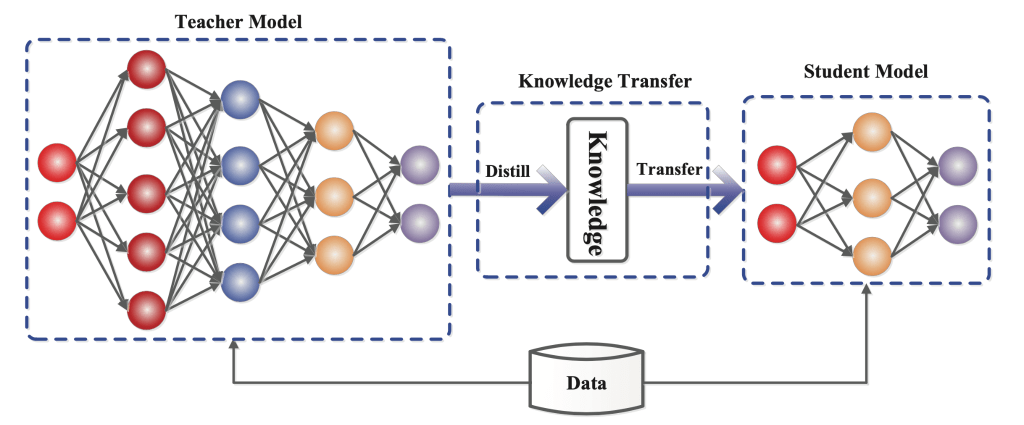
We therefore distilled our models using the standard word-level knowledge distillation technique (Hinton et al. 2015, Kim and Rush. 2016) which was used by Gumma et al. 2023 to compress IndicTrans1 models (now deprecated). We also used the seed data — BPCC-H Wiki subset for a final stage of fine-tuning to slightly improve the translation performance, however, this is optional and has minimal impact. We first distilled the English-centric models and then repurposed the distilled models, as before, to develop the compressed version of IndicTrans2-M2M.
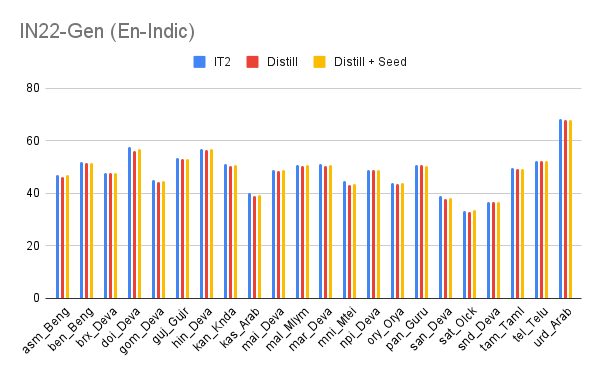
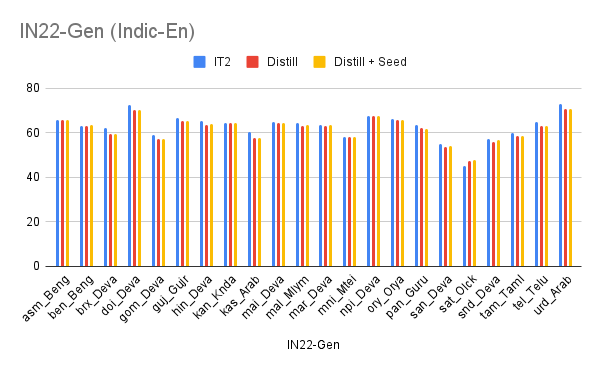
The plots below show a comparison of the original and distilled English-centric IndicTrans2 models. We were able to compress our English-centric models from ~1.2 billion parameters to ~250 million parameters, a 5x reduction in model size. The compressed IndicTrans2-M2M contains ~350 million parameters, follows a similar trend. Overall, we observed that the distilled models, which have only ~20% parameters, perform slightly poorer but have ~36% reduced inference time. To be precise, the inference time for decoding a test set goes from ~52s to ~33s. This means that where we would once need about 2 minutes for Indic-Indic translation via pivoting, we now need only 30 seconds with our compressed IndicTrans2-M2M model, albeit with some drops in translation quality.
We officially release on HuggingFace 🤗 our IndicTrans2-M2M model, its compact variant as well as the compact versions of the original English centric IndicTrans2 models (Indic-English and English-Indic). Our models are released with a MIT license and can be used for both research and commercial purposes. Kindly feel free to try them out and use them in your applications. For technical details, check out IndicTrans2 paper (now accepted to TMLR) and its GitHub repo. Feedback is always appreciated.