

Introduction
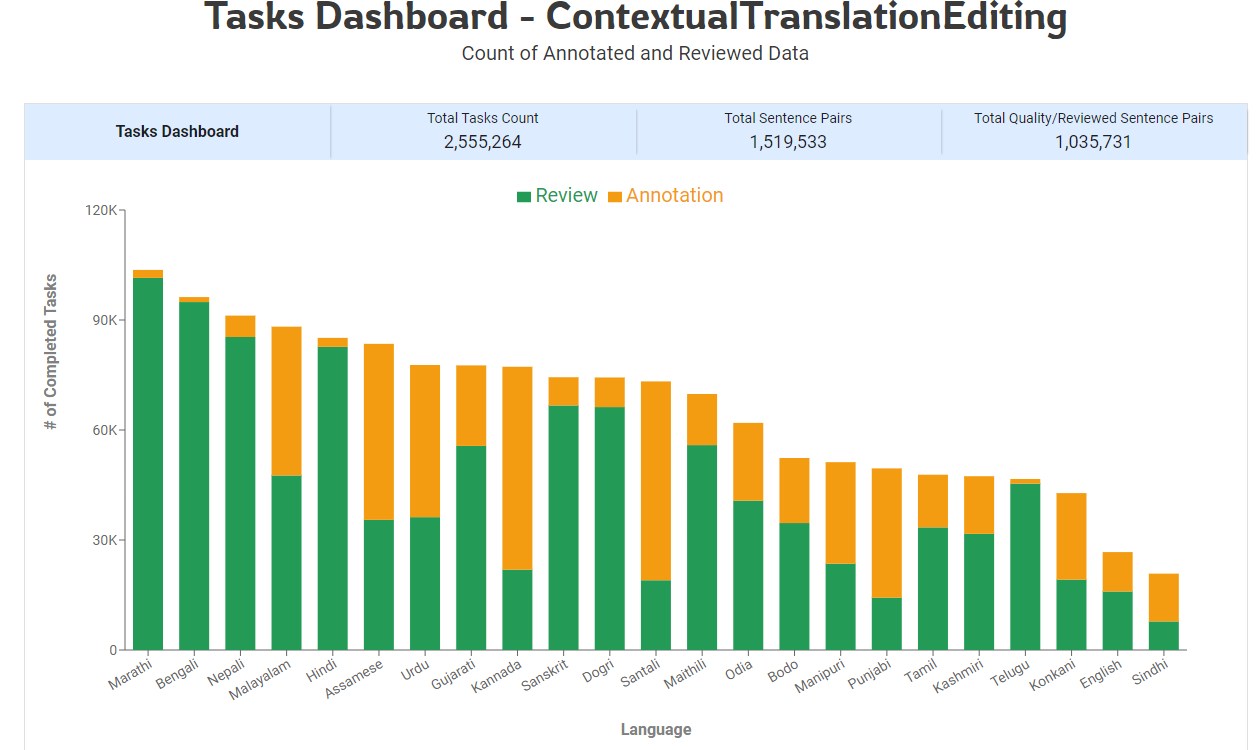
Shoonya is an open-source AI-powered data annotation platform with an integrated workforce management system, that has been built with a vision to enhance the digital presence of Indian languages. At AI4Bharat, a large team of language experts annotate the data in all the 22 official languages of India on Shoonya, which is then used for creating open-source dataset repositories, which, in turn, are used for training open-source machine learning models being developed by AI4Bharat. Shoonya currently supports contextual verification and translation of sentences and transcription of audio and OCR files.
A highlight of Shoonya is that it has been built incorporating the invaluable feedback of hundreds of language experts using the platform real-time. This has resulted in ensuring that the platform is scalable, handling the huge number of simultaneous request loads.
The Technology Behind It
Shoonya is built with Material UI in the frontend and Django REST Framework in the backend. It uses PostgreSQL as the database and integrates the open-source data labeling platform, Label Studio for building its annotation system.
Leveraging open-source models (IndicASR and IndicTrans) developed by AI4Bharat, Shoonya can auto-generate transcription for audio files and translation for sentences. AI4Bharat Open-Source transliteration model (IndicXlit) is used for typing in Indian languages. Support for ‘right-to-left’ typing for languages like Urdu is also available.
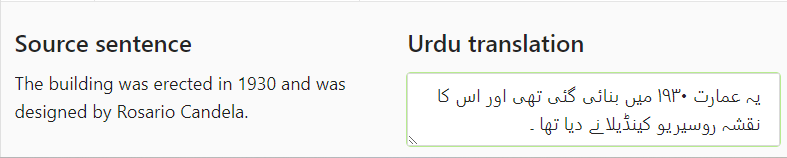
AI4Bharat’s open-source Indic Glossary is also integrated with Shoonya to help the language experts with translations at word-level.
Making collaboration as well as management easier is the hierarchical arrangement in Shoonya comprising Organization, Workspaces, Projects and, at the granular level, tasks (the data item to be annotated) and its annotations, with each module having its own pre-defined permission and access control. This hierarchy lets more than one organization exist on the same platform, with the data of each organization restricted to itself.
Even an annotation goes through a hierarchical quality check, with a data item first annotated, then reviewed and finally super-checked within Shoonya itself. This multi-layered annotation, review and supercheck workflow for a task ensures that the final data is of high quality.
Even the source sentences to be translated first goes through the verification stage and only those sentences identified as being clean and grammatically correct are translated. The users can skip annotating any task which they feel does not meet the quality requirements.
Workforce Management System
The Organization, Workspace and Project has various user roles associated with it, each following its own hierarchy, with each role having the authority to perform all the activities allowed for the roles below that level. This helps in easier workforce management.
Every organization using Shoonya has its own organization database created for it. Each organization will have a set of workspaces, which offer a flexibility to categorize projects on the basis of language, annotation type, domain, the annotator team, etc. The users are given the option to belong to multiple workspaces
Every workspace has its annotation tasks being grouped into different projects, with each project belonging to a specific language and an annotation type like translation, transcription, etc. Every project has its own set of language experts. A multilinguist has the flexibility to work on multiple languages.The actual data annotation work happens within a project. With multi-layered quality checks being supported, there are separate user roles to cater to these within a project.
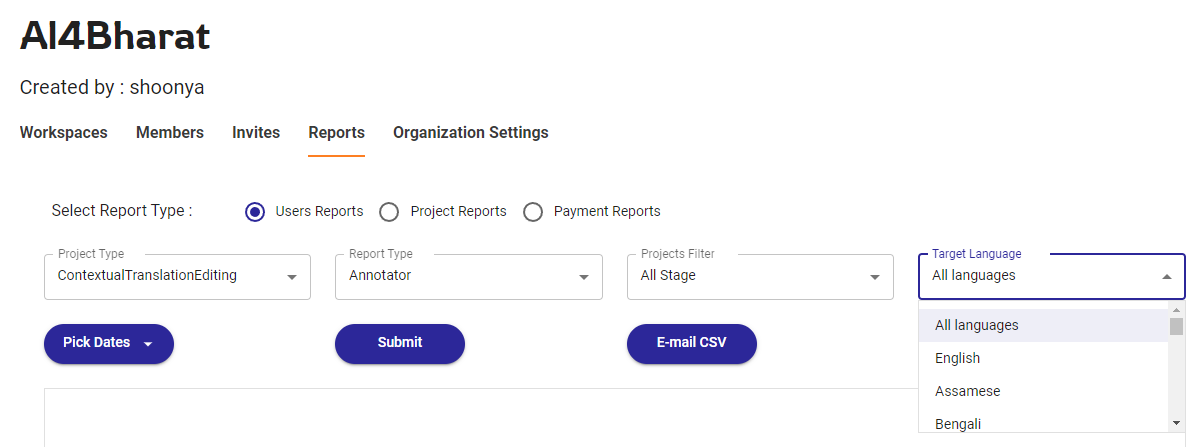
Enabling Performance & Progress Tracking through Reports
Shoonya provides both user-based and project-based reports at all levels of the organization structure. This helps the users of all users to keep a track of the project progress as well as the user performance. These reports can be filtered based on language or the quality-check level. Users also have the option to have the reports and their daily progress sent over an email.
The reports provide all the statistics related to the tasks either at the user-level or project-level as selected – the number of tasks and the different statuses the task and its annotations are in, the date when they were completed and the number of times a task failed a quality check. Other metrics related to the task like the word count, sentence count and average word error rate (for text-based annotations) and the transcribed hours (for audio-based annotations) are also shown.
Data Management System
Dataset Instances
Shoonya has a ‘Datasets’ module which has different dataset instances representing each type of data that can be annotated on it. Each dataset instance will have multiple datasets of its type and each dataset will have data items to be annotated. These are the dataset instances currently supported in Shoonya:
- Sentence Text – A sentence, its context, its language, domain and quality check status and human-corrected version of the sentence.
- Translation Pair – A source sentence, its context, its source & target languages, its machine translation & human-verified output translation, labse score & rating.
- Conversations (text) – A conversation in text format and its metadata, quality check status, its source & target languages, its machine translation and human-verified output translation.
- Speech Conversations (Audio) – an audio file and its metadata, its language, machine-generated transcript and human-verified transcript
- OCR Documents (Images) – an image file and its metadata, its language, machine-generated OCR prediction & human-verified transcript
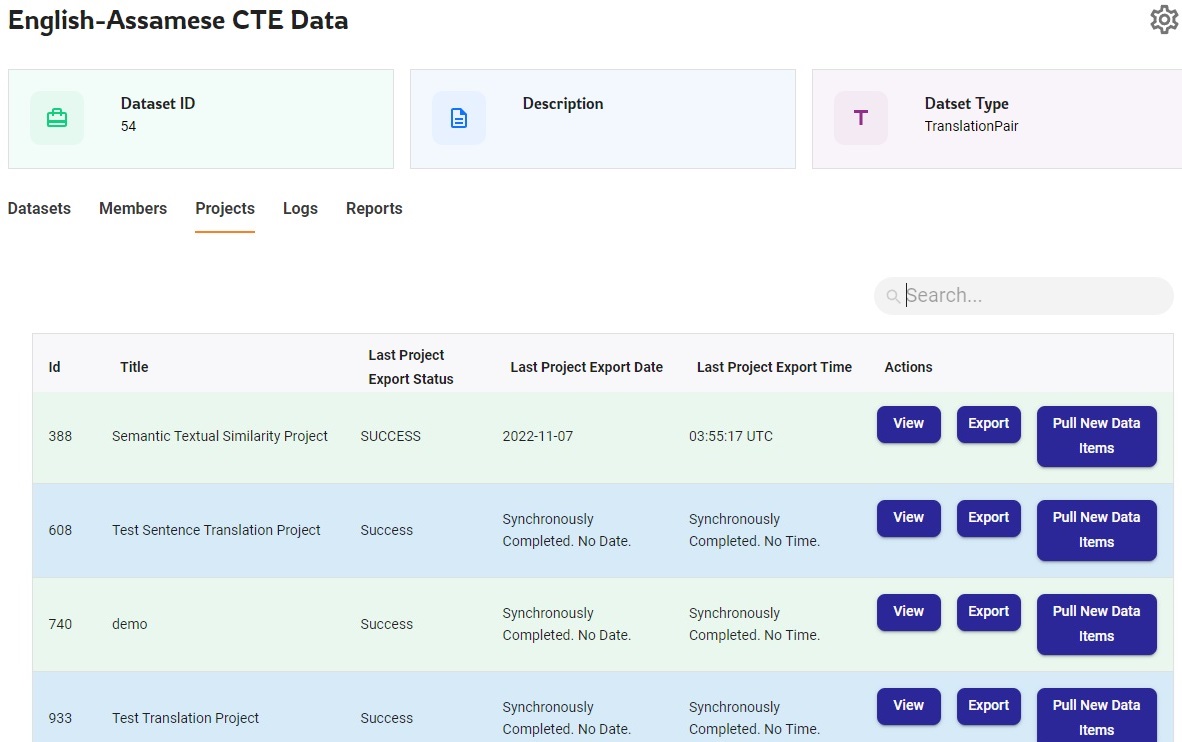
Datasets and Projects Mapping
There is a separate project type in Shoonya for every type of annotation that can be done on a dataset instance. Each project belongs to a specific project type and language and uses the data items from a dataset. For example, a contextual translation editing project will use the ‘Translation pair’ dataset instance.
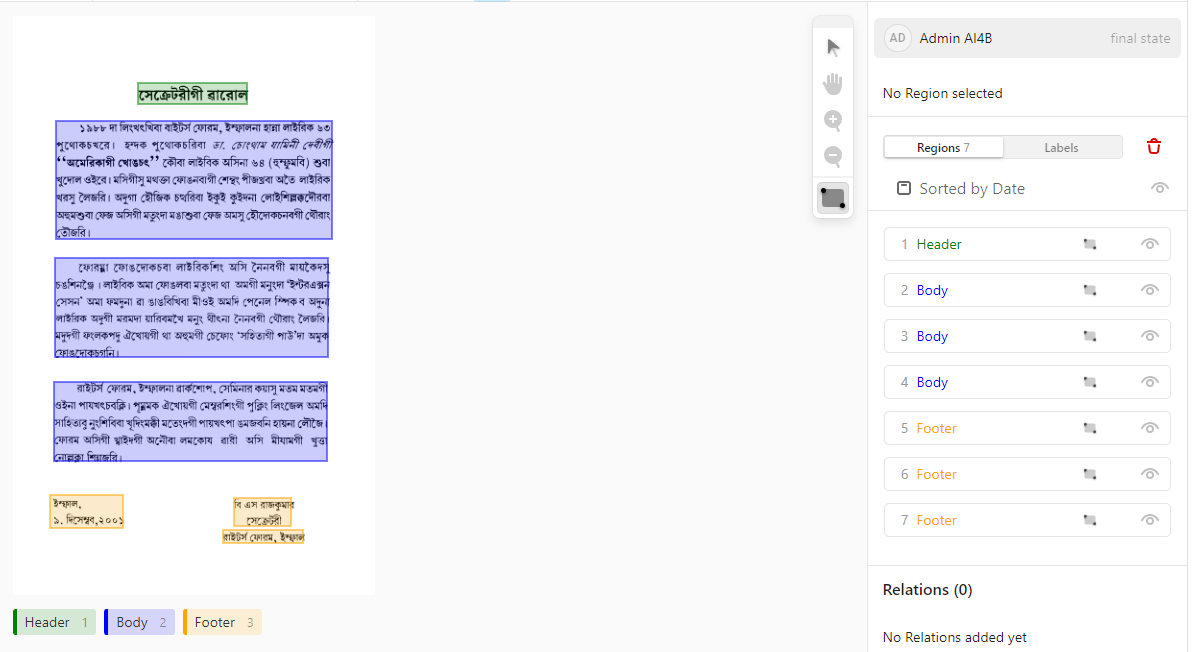
Each project will have a set of tasks, with each task representing each data item from that dataset that has to be annotated. For example, a sentence translation project task will have a source sentence that has to be translated and its output translation will initially be blank.
Once the user completes the annotation of a task, its final quality-checked annotation version is exported back to the source dataset. For example, the output translation entered by the user for a task will be copied as the output translation of the corresponding data item of the dataset.
Data Management Features
Shoonya offers a user-friendly interface to handle all the data processing work from the platform itself, without the need to access the backend. There is a user interface for everything from creating new dataset instances and uploading/downloading datasets, creating and downloading projects and the various reports associated with it and also accessing the error logs.
The Annotation System
Every task of a project has a status and it changes through the lifecycle of a project depending on the transitions its annotation(s) go through. Each task has separate versions of annotations belonging to the annotator, reviewer and the superchecker. But, a task has only one quality-checked version marked as its correct annotation.
Each annotation has an annotation status linked to it. This, again, indicates whether an annotation is yet to be annotated or is in progress or has been skipped by the user or has been rejected by the reviewer/superchecker or has finally been completed.
The Annotation Interface
Every project type has its unique annotation interface with the user shown the data to be annotated, its context, its machine-generated annotation along with other metadata like, say speaker details for an audio. The users can enter their own verified output annotation in the given text areas. The users can put the annotation into different statuses here.
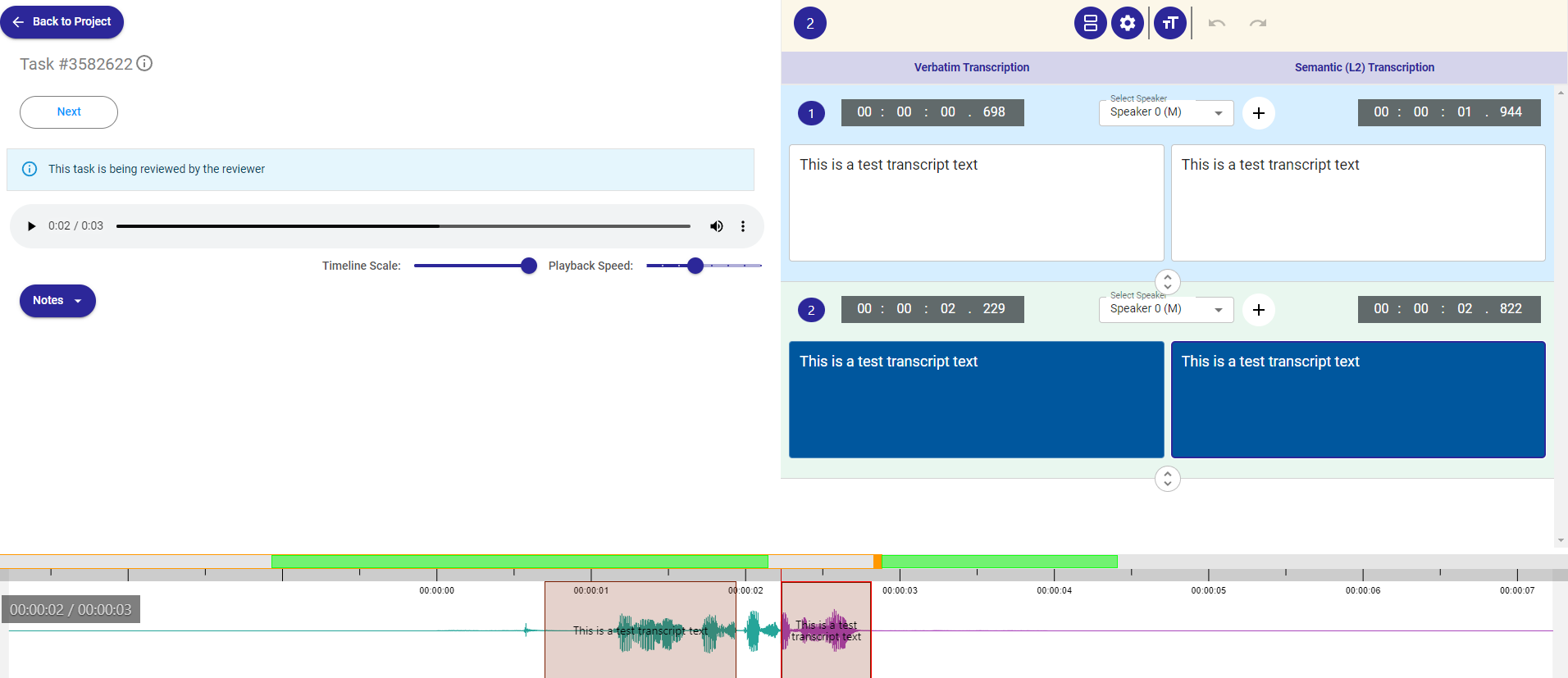
The Annotator-friendly Features
- The users can manage their assigned task count by choosing the number of tasks to be assigned and deallocating their tasks at any point of time.
- Shoonya provides machine-generated annotations and in-built transliteration and glossary features, which significantly reduces the time taken by a user to complete a task.
- Shoonya has an in-built annotation feedback mechanism in which the users can enter optional notes for each annotation in the annotation page itself. This facilitates easy sharing of feedback between annotators, reviewers and supercheckers.
- Shoonya lets the user track their own work across all their projects through the user’s progress reports.
Conclusion
For any organization passionate about creating, digitizing and annotating content in Indian languages, thereby bridging the divide between the Indian language speaking community and the advancing AI technologies, Shoonya is the open-source platform to turn to.
“For any further inquiries or communications regarding Shoonya, please feel free to reach out to Aparna at aparna@ai4bharat.org.”