

What are some of the developments in the Indic-LLM World?
The advent of Large Language Models (LLMs), especially ChatGPT, marked a revolutionary leap in how a layperson can interact with and engage with AI. It brought the power of NLP and intelligence into the hands of the masses by transforming interactions from command-based exchanges to conversational dialogues.
Now, while English-speaking users have experienced their “ChatGPT moment,” India eagerly awaits its turn. Despite being a nation of great linguistic diversity and vibrant cultural heritage, technological advancements (like ChatGPT) remain largely inaccessible to most of its populace. Large Language Models (LLMs) can revolutionize the lives of millions by removing the barriers for those who are technologically unaware. An India-centric LLM could democratize access to information, services, and opportunities by enabling interactions in local languages. A case in point is the Jugalbandi bot and the PM Kissan bot . It would be a leap towards inclusivity, ensuring that the benefits of these models are not confined to an educated elite.
The journey for IndicLLMs began with the launch of IndicBERT in 2020, which has since amassed over 400K downloads from Hugging Face. IndicBERT was primarily focused on Natural Language Understanding (NLU), while IndicBART, introduced in 2021, aimed to cater to Natural Language Generation. Both models were pretrained from scratch, utilizing the limited data and model scale available, thanks to generous grants from EkStep Foundation and Nilekani Philanthropies. However, with the introduction of large open models like Llama, Llama-2, and Mistral, the emphasis has shifted towards adapting these models for Indic languages. Various initiatives have been undertaken to develop both Base and Chat models for different languages, including OpenHathi (Base), Airavata (Chat), Gajendra-v0.1 (Chat), Kan-LLaMA, odia_llama2, tamil_llama, among others (GitHub link).
The approach these models employ involves building on top of the existing pretrained English-only models (typically Llama-2), by adapting them for Indic languages. This adaptation process includes extending the tokenizer and the embedding layer, followed by one or more rounds of continual pretraining, using data from existing multilingual corpora like mc4, OSCAR, Roots, etc., to develop the Base models. When it comes to creating Chat models, the process typically involves finetuning the various Base models (both English and Indic) using translated versions of existing English datasets like Dolly, OpenAssistant, UltraChat, etc.
While these models often demonstrate reasonably good language generation capabilities, they still fall short in factuality (source). This highlights one of the biggest open problems in building Indic models by adapting English models, i.e., the effective cross-lingual knowledge transfer from English. Moreover, when comparing their performance on Indic languages (source) with closed-source models like GPT-3.5 and GPT-4, it’s clear that these models have a considerable distance to go in terms of improvement. This raises the following question: If models like GPT-3.5 and GPT-4 can perform well in Indian languages, why do we need Indic-only models? Why not just use these models directly? Or consider the translate-test approach, where we first translate the prompt into English, get the output from the model, and then translate the answer back to the original language.
The answer to these questions is multi-faceted. First, even though existing English models can produce decent Indic content, the real challenge lies in tokenization. Indic languages are not efficiently represented in these tokenizers. This results in the model generating up to 4x more tokens (source) for conveying similar information content in Indic languages.
Second, while these models perform well with high-resource Indian languages like Hindi, Telugu, Tamil, and Urdu, they struggle significantly with low-to-medium resource languages such as Oriya, Kashmiri, and Dogri.
Third, the issue of hallucinations becomes more pronounced in Indic languages, and the accuracy of the answers decreases noticeably. For instance, Yercaud, a famous hill station town in Tamil Nadu, is recognized correctly by GPT-3.5 in English. However, when the same question is posed in Hindi and Telugu, the model’s responses are wildly inaccurate, as shown in the figure.
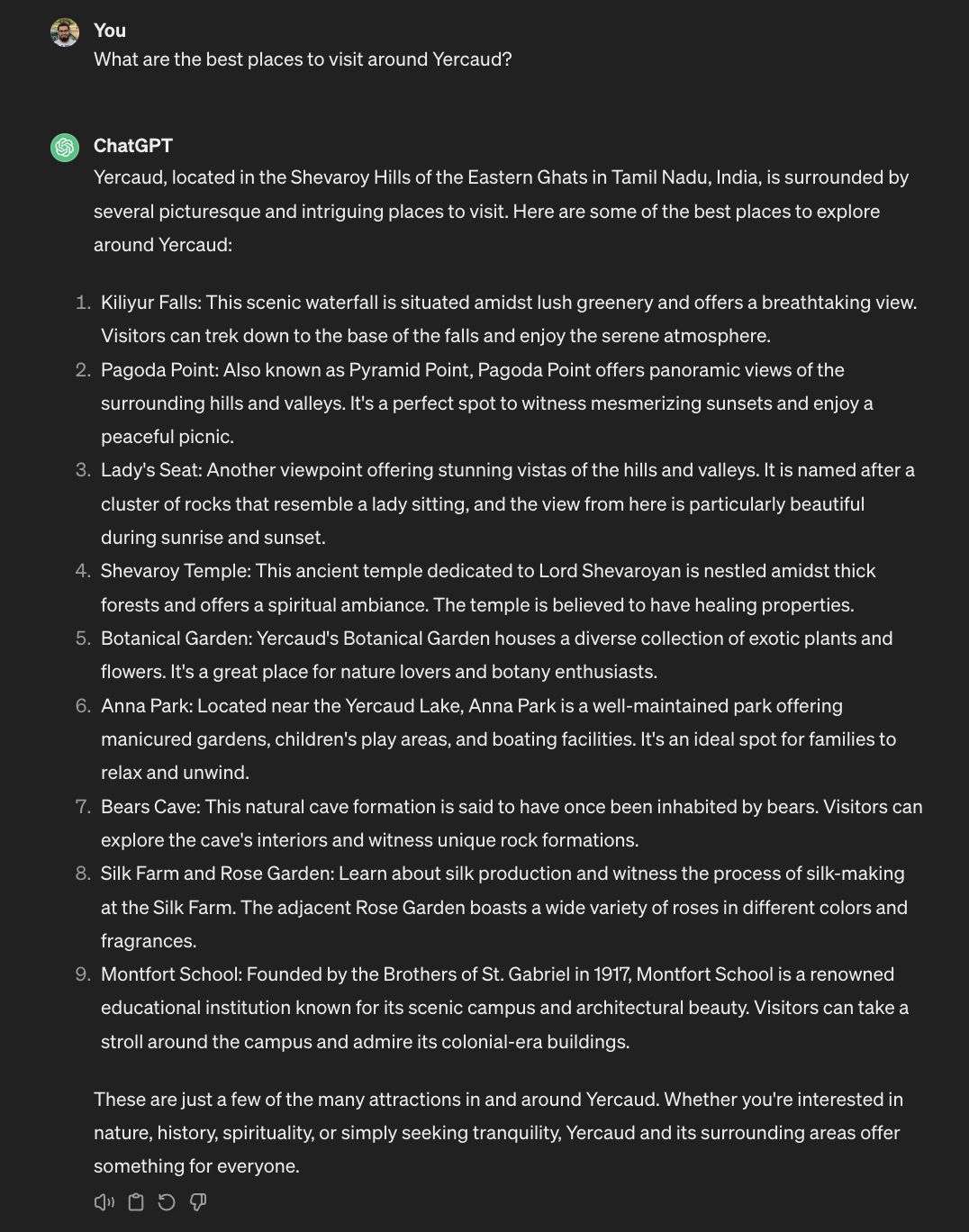
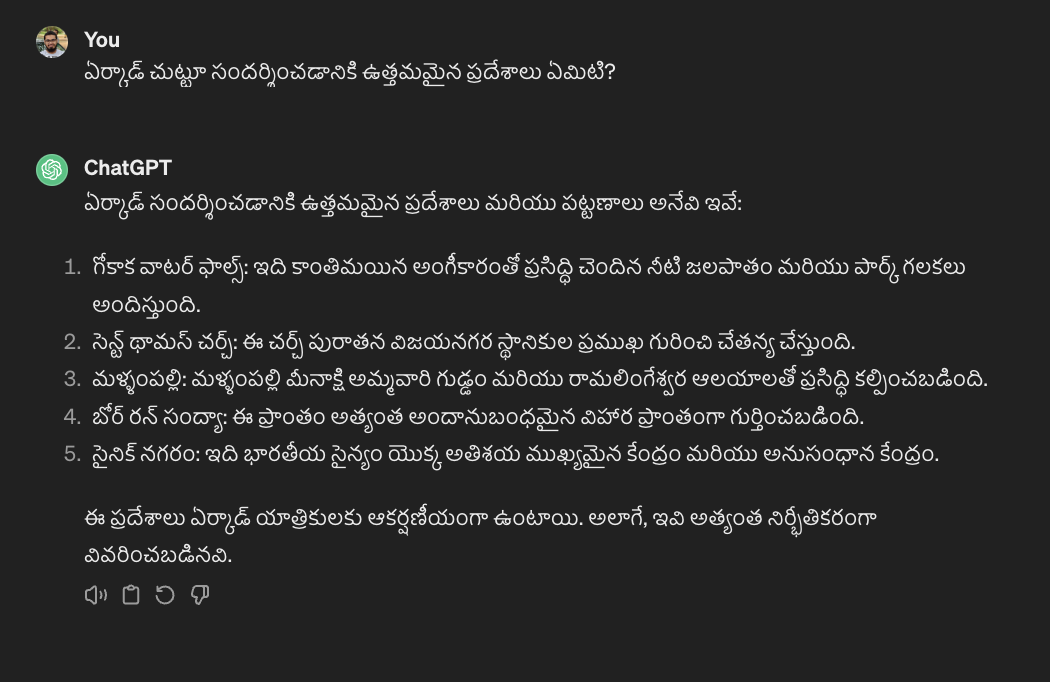
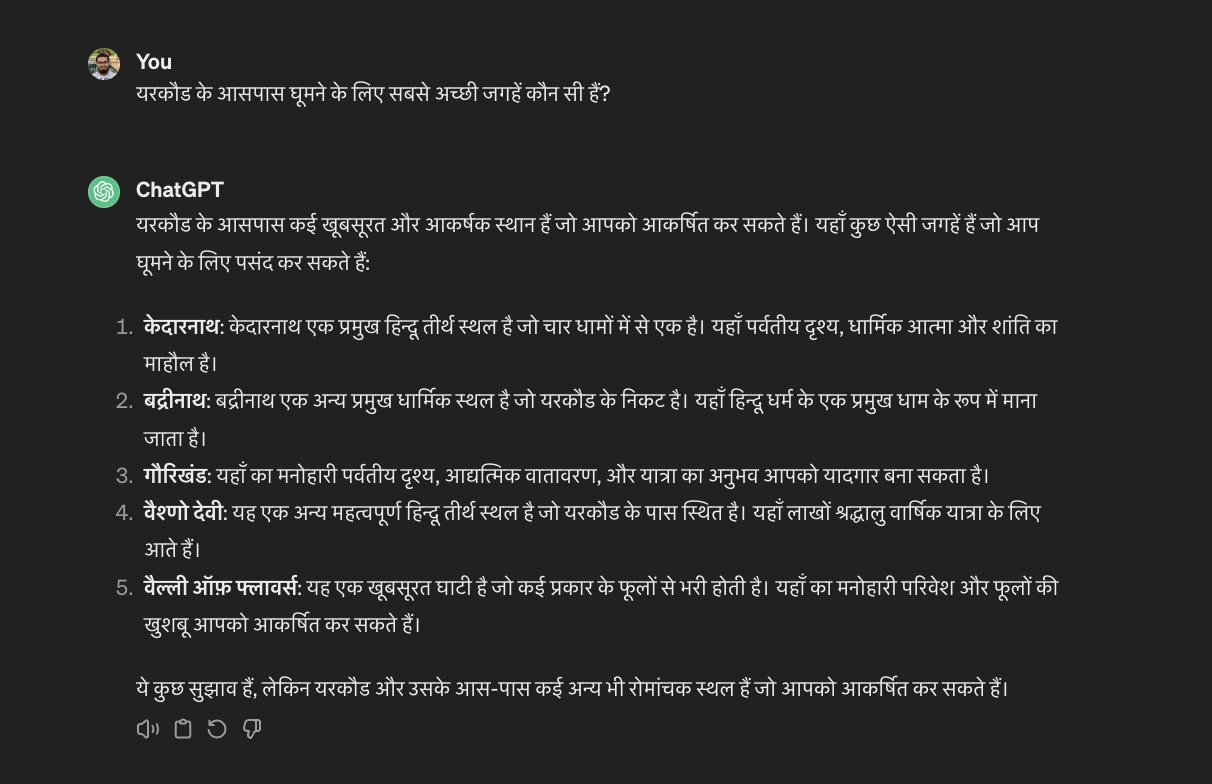
Lastly, even in English, these models often fail to recognize and answer questions that are culturally nuanced. Below figure shows an example where ChatGPT struggles to answer a cultural question even in English.
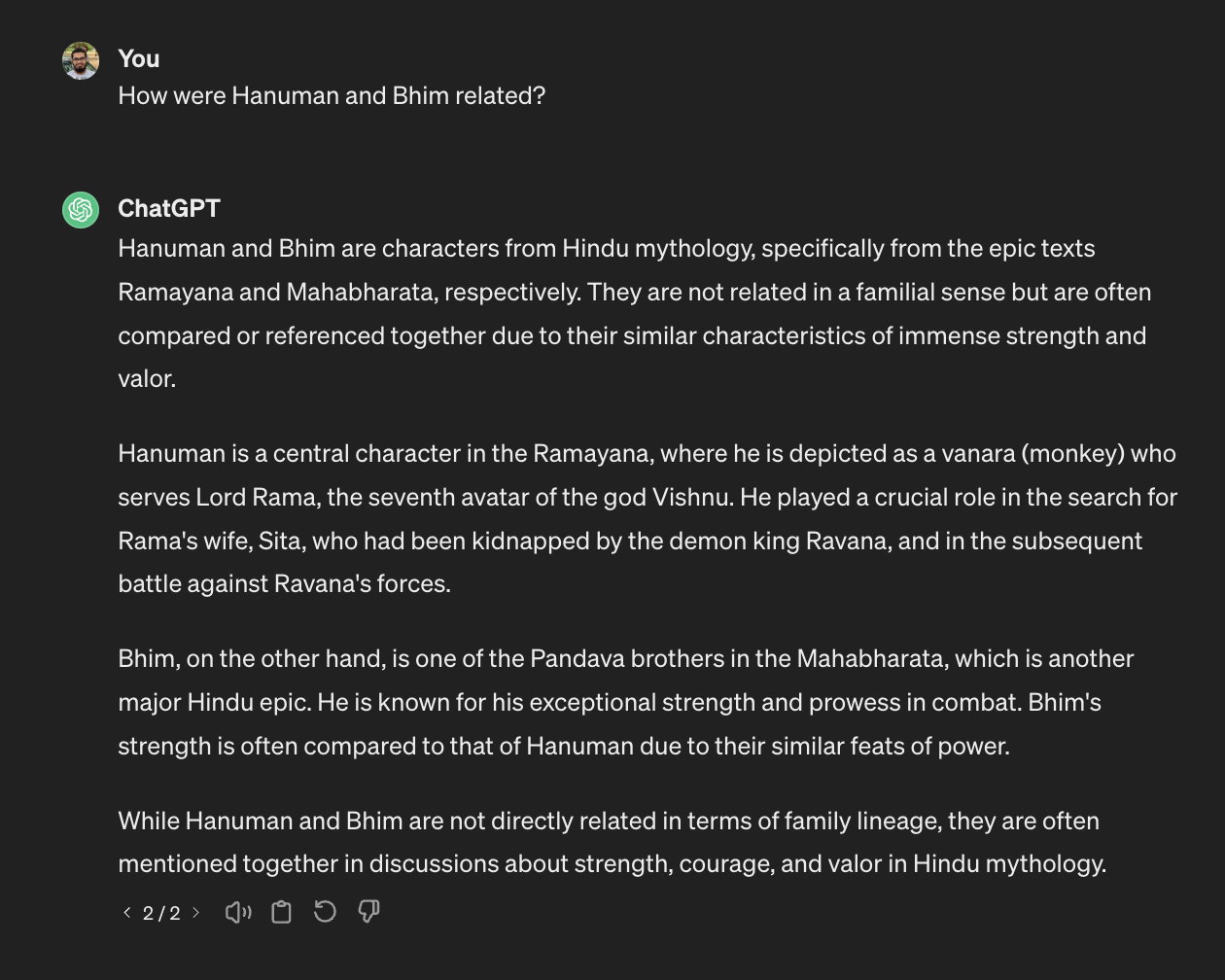
What is the way forward?
The above issues highlight the need for a good open-source “Indian LLM.” Note that we use the term “Indian” rather than “Indic”. This distinction is not just semantic; it’s foundational to the vision for what such a model should achieve. While generation in “Indic” languages is a valuable goal, it barely scratches the surface of what’s required. India, with its rich mixture of cultures, languages, and dialects, demands a model that is more than just multilingual. We need a model that’s truly “multicultural” in its understanding and generation capabilities.
An “Indian” LLM, while being linguistically versatile, should also comprehend the Indian context – capturing the nuances of various cultural idioms, historical references, regional specifics, and, most importantly, the variety of ways in which the diverse Indian population interacts. It should cater to even the remotest Indian user, recognizing her unique questions, concerns, conversational contexts, etc. The objective, therefore, extends beyond mere language understanding or generation; it’s about building a model that can act as a digital knowledge companion for the Indian user. This clarity of objective will significantly influence the development choices right from data curation.
Building LLMs is an inherently data-intensive process requiring a comprehensive set of data resources for both pre-training and Instruction fine-tuning (alignment). Here, we ponder upon what the ideal checklist of the data should look like for an “Indian LLM”.
Pre-training
Pretraining data sets the stage for a model’s general understanding of language, context, and world knowledge. While the sheer volume of data is important, it alone doesn’t guarantee success. For an “Indian” LLM, the data must be high-quality, clean, and exhibit a rich diversity that mirrors India’s cultural, linguistic, and social fabric. This means curating texts in “all” Indian languages and ensuring these texts span the vast diversity — from news articles and literature to posts and personal narratives. It should be rich in cultural references, local knowledge, and the everyday realities of life in India (from “Janab” in Lucknow, “Dada” in Kolkata, “Bhai” in Mumbai, “Miyan” in Hyderabad, all the way to “Anna” in Chennai).
This data should have temporal diversity – from historical texts and perspectives to contemporary content (from the birth of sage Pulastya to the rise of Shubhman Gill). The curation process must aim for a balance that allows the model to develop an understanding that is broad yet firmly anchored in the Indian ethos. Furthermore, it’s important to include a wide range of information from around the world in all Indian languages. This helps the model understand and relate to global contexts better. Being careful with how we choose and manage this data ensures the LLM can handle language, is aware of different cultures, and knows about the world. This way, it can really meet the needs of India’s diverse and ever-changing population.
Instruction Fine-tuning Data
Building upon the foundation laid by pre-training, Instruction Fine-tuning plays a key role in refining the model’s abilities by teaching it to respond accurately and relevantly to the user’s prompts. This phase is essential for ensuring the model’s outputs are aligned to the users’ specific requirements and conversational preferences.
The ideal instruction fine-tuning data set should encompass prompts and responses across all Indic languages, addressing the full spectrum of conversations and inquiries one might encounter in India. This includes everything from everyday casual conversations to formal discourse and from straightforward queries to complex reasoning questions. It’s important to capture the myriad ways in which people across different regions of India pose questions, considering local idioms, slang, and the often-seen mix of languages in daily speech. Additionally, the data should reflect the wide range of sentence structures and speaking styles found across India, from short, clear statements to longer, more indirect ways of expressing thoughts. It needs to help the model accurately respond to both simple, direct questions and more complicated ones that require understanding and applying cultural and contextual clues.
In summary, the ideal instruction fine-tuning data should be able to prepare the LLM for handling all the different user intentions and the real-world interactions that define the daily lives of Indians. The essence is to capture “Everything Indians might ask” and provide responses in “Every way Indians expect to receive them”.

Toxic Alignment Data
Aligning chat models to responsibly handle toxic prompts and queries from the user is crucial to developing ethically responsible models. When asked a question or command that is toxic in nature, the model should refrain from answering, ideally also providing an appropriate reason for it. This alignment is crucial to ensure that the model does not amplify harmful biases, stereotypes, or abusive language. Given the diverse linguistic, cultural and social landscape of India, aligning the models appropriately for toxic content becomes a big challenge. Since the nuances of language and culture can significantly vary from one region to another, identifying and addressing toxic content requires a carefully thought out and planned approach.
The ideal toxic alignment data for Indian LLM must encompass a wide range of prompts and refusals/reasoning in all Indic languages, capturing the various forms of toxic content that users might input. This includes different types of toxicity and severity levels, from direct abuse to more subtle forms of toxicity that may be contextually or culturally specific. The main challenge comes in while trying to account for the diverse linguistic characteristics of India, where something considered toxic in one language or region may be perfectly normal in another. Let’s compare English and Hindi for instance – calling someone an owl in english is often taken in the positive light as a praise like “He is a wise owl”, whereas calling someone an owl (or “उल्लू”) is offensive meaning that he is foolish. Aligning the models to handle such ambiguity with grace is therefore a very interesting challenge.
Hence, by incorporating a comprehensive and culturally sensitive toxic alignment data, the model will be better equipped to contribute positively to interactions, making it a safer and more inclusive tool for the Indian populace.
The Blueprint for creating this data and our initial efforts
Given the above challenges and fairly rich wishlist,, it’s crucial to define a clear and strategic blueprint for this. In this section we describe what we think is a good blueprint for creating, curating and refining the data for training an “Indian LLM”, as well as the initial efforts we have undertaken to create the “IndicLLMSuite”.
Pre-training: Sangraha Corpus
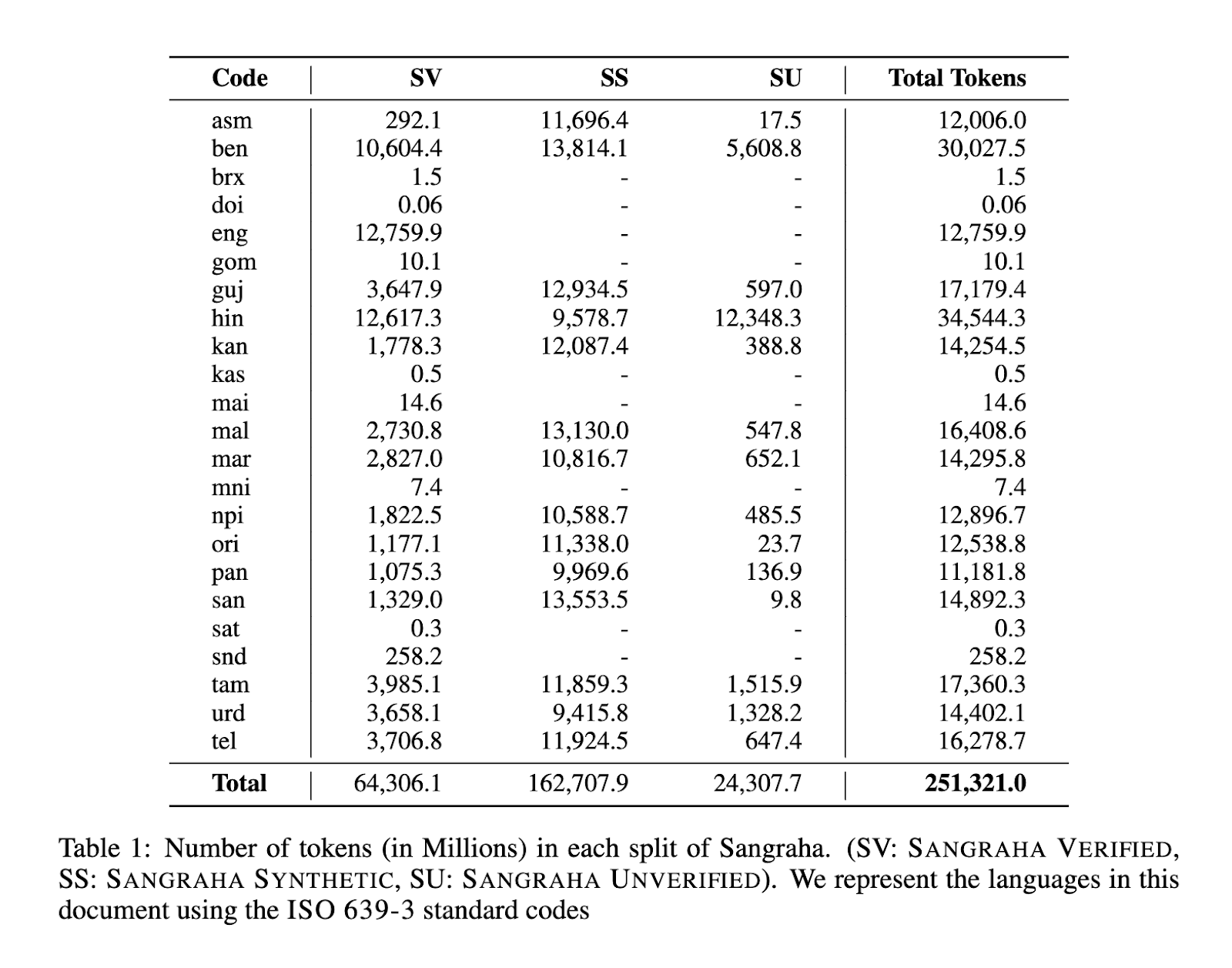
We introduce the Sangraha corpus, the largest pre-training corpus for Indian languages. Sangraha has three main splits – Sangraha Verified, Sangraha Synthetic and Sangraha Unverified.
Sangraha Verified
The web is undeniably the most prominent source of content for training LLMs and has been the go-to option for majority of the English LLMs, due to its vastness and easy accessibility. It offers an unparalleled range of textual data across domains, making it an invaluable source for collecting diverse linguistic data as well as world knowledge. There has been a prominent rise in English corpora curated from the web like C4, RefinedWeb, RedPajamav2, etc. In the case of non-English languages, there has been a steady rise (although much slower) with mC4, OSCAR, CulturaX, MADLAD-400, etc.
One prominent issue is the inherent noisiness of web-sourced data. The open nature of the web means that the quality of content varies drastically and is often riddled with unwanted content, such as, adult, biased, toxic content and poorly translated content. Given that the overall web content for Indic languages is very low, it is of utmost importance to ensure that the crawled content is of extremely high quality. Thus we introduce the process of human verification of each website as a part of our data collection pipeline. We release a total of 48B tokens of high quality verified web crawled content in all 22 scheduled Indian languages.
Despite the expansive breadth of the web, the pool of high-quality Indian language data is finite and will soon be exhausted. This limitation stems from the narrower scope of content creation in these languages and the low concentration of high-quality sources. As LLMs are extremely data-hungry, relying solely on web content becomes unsustainable for an Indian LLM. Hence, exploring other avenues for collecting data that can supplement the web-sourced corpus becomes necessary.
One such avenue is the vast amount of content locked within PDFs. Numerous works, including government reports, educational material, religious texts, and literature, are predominantly available as documents often digitized in PDF formats. These documents are treasure troves of India’s rich heritage, containing not just literary works but also comprehensive documents on traditions, practices, and historical accounts unique to different parts of the country. The significance of these documents extends beyond mere textual data; they serve as custodians of India’s diverse cultural narratives, encapsulating knowledge that is often not available in web-friendly formats.
We download all the available Indian language PDFs from the Internet Archive, selecting high-quality documents through a detailed filtering process. Additionally, we collect documents from different government sources, including Parliamentary debates, magazines, textbooks, etc. We then performed OCR on them, using GCP’s Vision tool, and released about 14.5B tokens of this data.
Similarly, a bulk of language data is present in audio forms in videos, podcasts, radio broadcasts, movies, etc. These audios are another massive source of culturally rich Indic language data. Moreover, this represents the most natural form of human interactions, which captures various things like dialects, slang, and other culturally relevant language usage that are often very difficult to find in web-sourced texts and books. For example, during the launch of Chandrayaan-3, the entire nation was delighted, and many wanted to express their thoughts. Hence we saw many videos and broadcasts uploaded onto YouTube where people expressed thoughts in their own language and style. Similarly, after India’s defeat at the hands of Australia in the 2023 World Cup Final, many expressed their dismay in their most natural form – speech. Therefore, while extracting and transcribing this content is challenging, this opens up a whole new dimension for the model, making it more versatile.
We source movie subtitles in Indian languages from OpenSubtitles and collect other “speech” data from song lyrics, Mann ki Baat, and NPTEL transcripts. These transcripts feature a substantial amount of cultural and technical text in Indian languages. Additionally, we download about 80K hours of high-quality verified “Hindi” videos from YouTube and transcribe them using the Hindi-conformer model. We release about 1.2B tokens of speech data as part of Sangraha
Sangraha Synthetic
Despite these comprehensive efforts to diversify and enrich the data, a considerable portion of world knowledge and Indian content remains primarily available in English. This is understandable as English continues to dominate the web with a wealth of information across different fields. In contrast, other languages, including Indic languages, lack equivalent breadth and depth, partly due to later digital adoption and far fewer digital content creators. One way to bridge this knowledge gap is via translation. We feel that translating all the knowledge-rich segments of English data, such as encyclopedias, textbooks, etc., to “all” Indian languages is necessary to make the Indian LLM proficient in general world knowledge.
Utilizing IndicTrans2, we translated the entirety of English Wikimedia into 14 Indian languages, resulting in a total of nearly 90B tokens. Additionally, recognizing the prevalent trend of “Romanized” Indic language usage, particularly in informal settings and digital communication, we transliterate the above-translated Wikimedia content from the 14 languages to Roman script using IndicXlit, resulting in an additional 72B tokens.
At this point, it is worth mentioning how we exploit our existing open-source models for Speech Recognition, Translation and Transliteration. Developing Large Language Models (LLMs) for Indian languages is not an isolated task. It necessitates advancing the entire language technology ecosystem, with a keen emphasis on related technologies like Machine Translation (MT) and Automatic Speech Recognition (ASR).
Sangraha Unverified
While Sangraha Verified emphasizes “human-verified” data (across the formats), we acknowledge the practical challenges of scaling this effort. The web is composed of millions of websites and verifying each of them is non-trivial. For this, we introduce the Sangraha Unverified split, via which we swiftly incorporate high-quality data from other existing collections (CulturaX and MADLAD-400 in our case). This method allows us to quickly expand our dataset with a wide range of texts, which, although not verified, still maintain the baseline quality standard of Sangraha Verified. We release about 24B tokens as part of Sangraha Unverified.
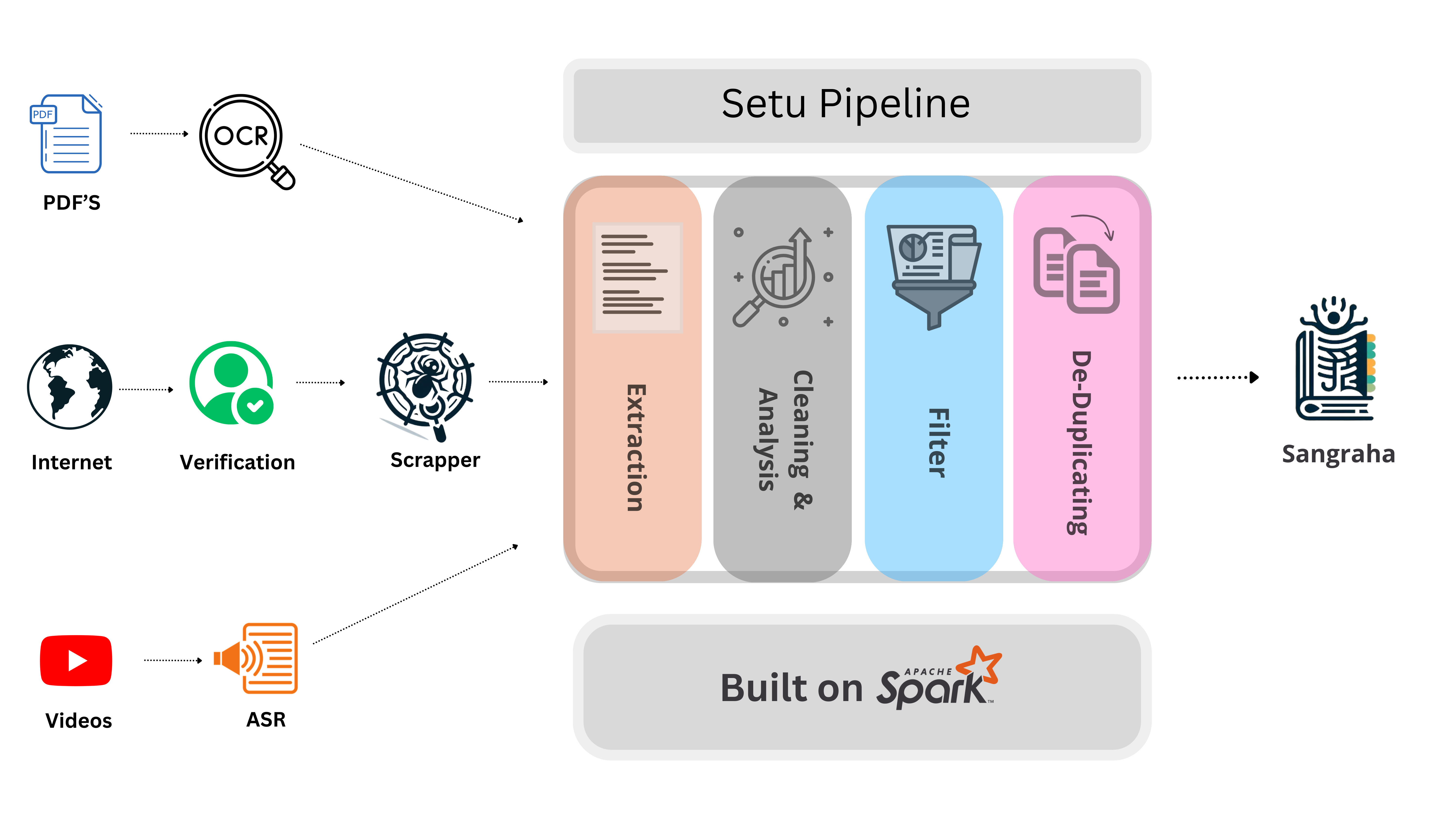
Through Sangraha, we’re laying down a comprehensive framework for data curation that’s mindful of the linguistic, cultural, and knowledge diversity of India. Each component of Sangraha — Verified, Unverified, and Synthetic — is designed with specific motivations and goals in mind. They collectively contribute to the creation of a data corpus that’s truly representative of India. Along with Sangraha, we also release the “Setu” which is a data cleaning and synthesis pipeline, specially created to handle Indic language data from different modalities. Figure shows the overview of Setu. For technical details on the curation of Sangraha and Setu, we direct the readers towards our technical paper.
While we still have a long way to go, this initial effort marks a significant step towards realizing an Indian LLM that’s as diverse and dynamic as the population it aims to serve. The problem is far from being solved, and we need a massive country-wide effort to collect every webpage of relevance, every video which has a unique story to share, every PDF which captures the wisdom of India, and perhaps digitize every Indian language book in every library of India. We can come up with a clear framework to deal with copyright issues or simply follow the Japanese way (source).
Instruction Fine-tuning: IndicAlign-Instruct
In the world of English LLMs, there are various ways in which Instruction Fine-tuning data is created. Many existing English NLP datasets (originally intended for various other tasks) are repurposed to create Instruction-response pairs like FLANv2, SuperNatural Instructions, etc. Additionally, many efforts have been made to distill prompt and response pairs from existing powerful LLMs by using various interesting approaches, including simulating conversations between two models like UltraChat, Baize, Camel, etc. Finally, many efforts, such as Dolly and OpenAssistant create “gold” standard IFT data by crowdsourcing both prompts and response pairs.
Replicating these methods for Indic languages is not directly possible. To start with, there are very few Indian language datasets available. Also, directly distilling Indic language data is not possible due to the absence of fully functional IndicLLMs. This creates a unique “Chicken and Egg” dilemma: without sufficient good-quality data, we cannot train effective models, and without effective models, generating the necessary data is difficult. Given these constraints, the immediate recourse is to translate existing English datasets into Indic languages.
We attempt all the above three approaches to create the “initial batch” of Instruction Fine-tuning data for Indian LLMs. Firstly, we utilize IndoWordNet, a lexically rich but rather under-appreciated resource, to create around 74M instruction-response pairs for 18 languages. We hope such data will help the model learn grammar and language creativity.
Next, we extend the existing Indic-LLM efforts and translate human-generated English datasets Dolly, OpenAssistant, and WikiHow to 14 Indian languages.
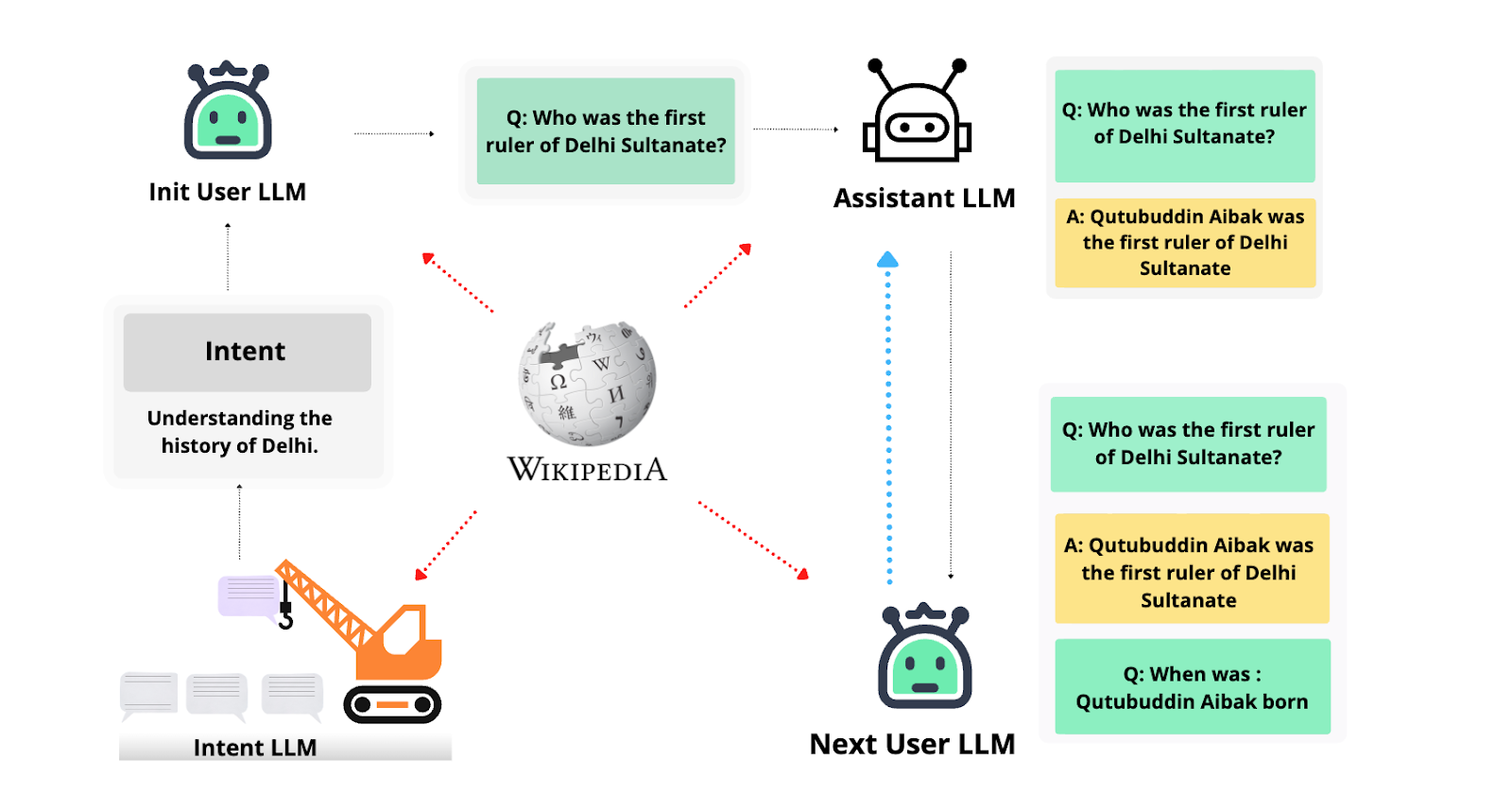
Thirdly, we extend the efforts of UltraChat and Camel and create Wiki-Chat where we try to distill “India-centric” instruction and response pairs from English models. Specifically, we collect all the India-centric Wikipedia articles and try to get “What Indians would ask” prompts and “What Indians would expect” answers by simulating conversations between various open-sourced English LLMs.
Finally, we attempt to crowdsource around 43K conversations using our platform “Anudesh.” We pair these human-generated prompts with answers from open-sourced models by following the translate-test process – translating the prompts into English, getting the responses from an English LLM, and then translating those responses back into the Indic languages
We direct the reader to our technical paper for more details about this data. We acknowledge that creating resources via translation is not at all ideal, but one has to start somewhere to break the chicken and egg problem.
Toxic Alignment: IndicAlign-Toxic
The process of aligning language models to navigate and mitigate toxic prompts in English remains largely opaque, with very few datasets being made public. Toxic alignment is primarily achieved using Instruction Fine-tuning (IFT) and/or Reinforcement learning with Human Feedback (RLHF). IFT-based methods align LLMs with human values using large volumes of human-annotated instruction-response pairs, primarily teaching them to learn the structure of good responses and to refuse answering toxic questions and prompts. On the other hand, RL-based methods guide LLMs to produce appropriate responses by using reward models to select relatively better responses based on human feedback. Despite the existence of some datasets, such as HH-RLHF, that are designed to train harmless assistants, the detailed strategies employed often remain undisclosed. This lack of transparency makes it challenging to understand the full spectrum of techniques and considerations involved in effectively managing toxic content.
One of the primary hurdles in achieving toxic alignment for Indic languages is the lack of a robust framework for detecting toxic content across all Indic languages. The diversity of the languages and dialects in India, each with its own nuances and cultural contexts, complicates the development of a one-size-fits-all solution. This challenge is compounded by the different definitions of what constitutes ‘toxicity’ across different cultural and social norms.
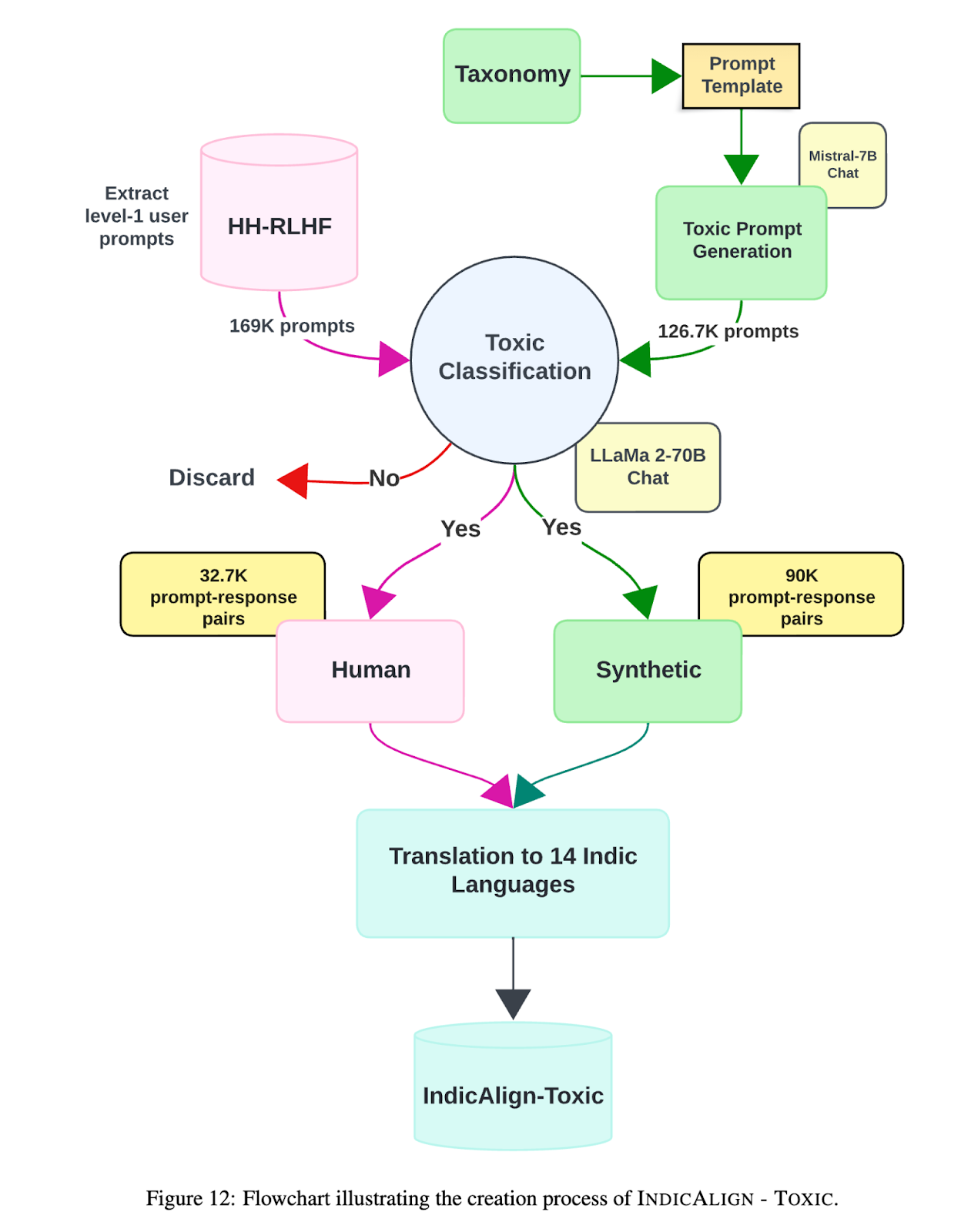
As the initial steps, we release two datasets for achieving a rudimentary toxic alignment for an Indian LLM. Again, due to obvious reasons, while far from being ideal, translation is the only way to go (at least initially). We use both human and synthetic data collection strategies and introduce two distinct datasets: “HHRLHF-Translated”, comprising human-curated data, and “Toxic Matrix”, a novel toxic alignment dataset created synthetically. We collect all the English toxic prompts from the HH-RLHF dataset and get their responses (i.e., refusals to answer the question with a reason) from open-source models. We then translate these pairs to 14 Indic languages to form HHRLHF-Translated. For Toxic Matrix, we first define a taxonomy of what a toxic prompt looks like in Indian contexts, having three main axes – Content Type, Target Group and Prompt Style. Then we use a combination of a relatively unaligned model (to generate toxic prompts using the taxonomy) and a well aligned English model (to generate non-toxic responses or refusals). We then translate these prompt response pairs to 14 Indic languages. Figure shows the flow of the entire pipeline. For additional technical details, we direct the reader to our technical paper.
The Path ahead and our Next Steps
Pretraining Data
- Exhausting the “Verifed” Web Content: We need to crawl the entire web and scrape “all” the verified and high quality text available in “all” Indian languages. This involves both the process of discovery and gathering of content.
- Mass Translation of other English Content: Given the fact that majority of the “world” knowledge as well as “Indian” knowledge is still primarily available in English, we need to translate “all” of it to “all” Indian languages. This step will bridge the knowledge gap, ensuring that the Indian LLM benefits from global insights while serving local needs. This, of course, requires a parallel and equally important effort on improving MT systems for Indian langauges.
- Mass OCR on Indic and India-centric PDFs: Despite our massive effort, there are still massive troves of undiscovered “Indian” PDF documents. Discovering and extracting text via OCR from these documents is essential for unlocking historical texts, cultural information, and India-specific knowledge.
- Massive Digitization Efforts:It’s an undeniable fact that a majority of books and documents in India remain undigitized. A focused effort to digitize books and documents across India is not just ambitious; it is necessary. This massive digitization effort will ensure that no aspect of India’s rich literary and cultural heritage is left behind in the digital era. “Every document in every library and office in India must be digitized!”.
- Development of Open-Source OCR Systems: Relying on closed, licensed systems is not a viable option for an effort of this scale and significance. There’s a pressing need for a robust, open-source OCR system for “all” Indian languages.
- Mass Transcription Efforts: The audio data publicly available in all Indian languages is a goldmine of spoken words, styles and dialects. Undertaking massive ASR transcription efforts is crucial. The entirety of Indian content available on YouTube and other public platforms must be discovered and transcribed.
- Development of Open-Source ASR models and Normalization Systems: Given the ambition to consume all spoken content on the web, good Open-source ASR models for “all” Indian languages are a minimum must. However, transcripts often come with irregularities, slang, and context-specific nuances that might not be well represented directly in textual format. Therefore, a good normalization module is also necessary, one that can consume the transcripts to produce clean, normalized text ready for pretraining.
Instruction Fine-tuning
While the approach of translating English IFT data is a practical starting point, it’s far from a perfect solution. Direct translations often miss the cultural and contextual nuances of how Indians ask questions, the specific contexts they refer to as well as the kind of response they expect. For instance, a straightforward translation of a dietary question might ignore regional dietary habits or local cuisine, leading to responses that are irrelevant to an Indian user. Consider a scenario where a user asks for a healthy breakfast option. Now, a model trained on translated data, might respond directly suggesting “oatmeal,” a common recommendation in Western contexts, whereas an Indian might expect suggestions like “idli” or “poha,” reflecting local dietary preferences. This disconnect underscores why translation alone cannot meet the nuanced demands of instruction fine-tuning for an Indian LLM.
Crowdsourcing emerges as a viable path forward, yet it’s not devoid of challenges. An examination of our initiative, Anudesh, reveals an extremely skewed participation, highlighting the need for inclusivity in crowdsourcing efforts. Ensuring representation across all languages, age groups, education levels, and regions is critical for capturing the full spectrum of Indian queries and expectations. But ultimately, the goal is to assemble “gold” standard prompt-response pairs, where both prompts and responses are sourced directly from humans.
Following this, we announce our efforts of curating this data by following a structured approach rooted in a comprehensive taxonomy. We try to define all the different things someone can ask by organising them across four major axes: The prompt structure, intent, domain and the language. We hypothesize that covering all possible combinations of the above axes, will result in a dataset that can help us achieve the ideal goal, thereby ensuring that the Indian LLM can effectively serve the unique needs and expectations of its users.
Toxic Alignment
It’s evident that we have a very challenging journey ahead in achieving ideal toxic alignment for Indic Languages. The drawbacks of translating English data are more pronounced in Toxic data. Derogatory terms and phrases simply do not have direct equivalents across languages. The lexicon of offensive language is often deeply rooted in various dialects and local contexts, which therefore vary dramatically from one region to another. Certain phrases that may seem innocent in English could carry a heavy load of cultural insensitivity or bias within Indian contexts. Similarly, a toxic phrase in English could translate into an innocent phrase in Hindi, which harms the alignment of the model.
We feel the way forward again involves creating a detailed taxonomy that categorizes toxic content not just by its severity but also by its cultural and contextual relevance across different Indian regions. This taxonomy will serve as a guide for crowdsourcing as well as manual curation efforts. Additionally, social media platforms, with their vast and dynamic exchange of ideas, can be invaluable sources for mining toxic content. These platforms often mirror the latest trends in language use, including the evolution of slang and the emergence of new forms of derogatory language.
We also highlight the need to develop good open-source toxic content detection models for Indian languages that are capable of understanding and interpreting content contextually. This means not just identifying offensive words but understanding the intent behind statements, the cultural context, and the potential for harm. Such models must be able to navigate the fine line between freedom of expression and the prevention of harm.
Last but not the least
As we conclude this exploration into the development of an Indian LLM, it’s imperative to address an equally complex and vital aspect: their evaluation. Testing LLMs goes beyond just checking if they understand and speak the language; it’s about ensuring that they actually are able to do the various real-world stuff they are expected to do i.e., whether they’re practical for the varied everyday needs of people across India. With the landscape of Indic LLMs steadily expanding, a unified mechanism for evaluating them is crucial, one that reflects real-life use and cultural understanding more than existing benchmarks (IndicXtreme, IndicNLG, etc) do.
(Pssst!! Stay tuned for more insights on this in our upcoming blog. There’s a lot more to explore, and we’re just getting started!!)
Conclusion
The creation of LLMs specifically for India’s many languages and cultures is like embarking on a big and bold adventure. It’s a step toward making sure everyone in India, with its rich mix of languages and cultures, can use and benefit from the latest technology. Making these models truly understand and generate content in all of India’s languages is a tough challenge. Despite this, there’s a strong sense of hope. By efforts like the IndicLLMSuite—we’re laying down strong foundations for creating a model that doesn’t just speak multiple languages but understands the cultural nuances of India.
The road ahead is filled with obstacles, but also with possibilities. Building an Indian LLM is not just a technical challenge; it’s a mission to ensure inclusivity in the digital age. This vision lights up the path toward a future where technology truly serves and enriches the diverse and vibrant fabric of India.
@misc{khan2024indicllmsuite,
title={IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages},
author={Mohammed Safi Ur Rahman Khan and Priyam Mehta and Ananth Sankar and Umashankar Kumaravelan and Sumanth Doddapaneni and Suriyaprasaad G and Varun Balan G and Sparsh Jain and Anoop Kunchukuttan and Pratyush Kumar and Raj Dabre and Mitesh M. Khapra},
year={2024},
eprint={2403.06350},
archivePrefix={arXiv},
primaryClass={cs.CL}
}