
IndicMT Eval: Bridging the Gap in Machine Translation Metrics for Indian Languages
Authors: Ananya B. Sai, Tanay Dixit, Vignesh Nagarajan, Anoop Kunchukuttan, Pratyush Kumar, Mitesh M. Khapra, Raj Dabre
December 05, 2023
In July 2023, we published our work on investigating the effectiveness of various existing metrics on evaluating translations from English to Indian languages. We released the data that was collected as part of this study in 5 different Indian languages: Hindi, Marathi, Gujarati, Tamil, and Malayalam using 7 state-of-the-art translation systems. This has detailed annotations of various error-types and their corresponding severities marked by our in-house language experts. We also propose a new metric that not only improves on the correlations in these languages but is also better at handling any perturbations in the text.
Our Motivation
Machine Translation (MT) has seen rapid growth, but the evaluation of MT quality remains a challenge, especially for languages outside the European sphere. Indian languages, with over a billion speakers, present unique linguistic features that traditional MT evaluation metrics might not accurately capture. This is where "IndicMT Eval" steps in, a study that not only reshapes our understanding of MT quality for Indian languages, but also throws light on the best metrics to be used for Indian languages.
Methodology: Crafting a Reliable Dataset
We adopt the MQM framework to gather human annotations at the segment level, where each segment could comprise one or more sentences. Bilingual experts, fluent in English and an Indian language, meticulously marked errors in translations, providing scores out of 25 for each segment.
Quality assurance was paramount. Preliminary studies with crowd-sourced annotators revealed subjectivity issues, which led to a refined approach using a guided interface with language-expert annotators to ensure consistency and reliability in annotations.

Results and Insights: A Deeper Understanding of Existing MT Metrics in Indic settings
Our experiments comparing the correlations of various metrics’ scores with human judgements reveal that traditional n-gram overlap metrics like BLEU are outperformed by neural-network-based, end-to-end trained metrics that have been exposed to Indian languages.
Quality assurance was paramount. Preliminary studies with crowd-sourced annotators revealed subjectivity issues, which led to a refined approach using a guided interface with language-expert annotators to ensure consistency and reliability in annotations.
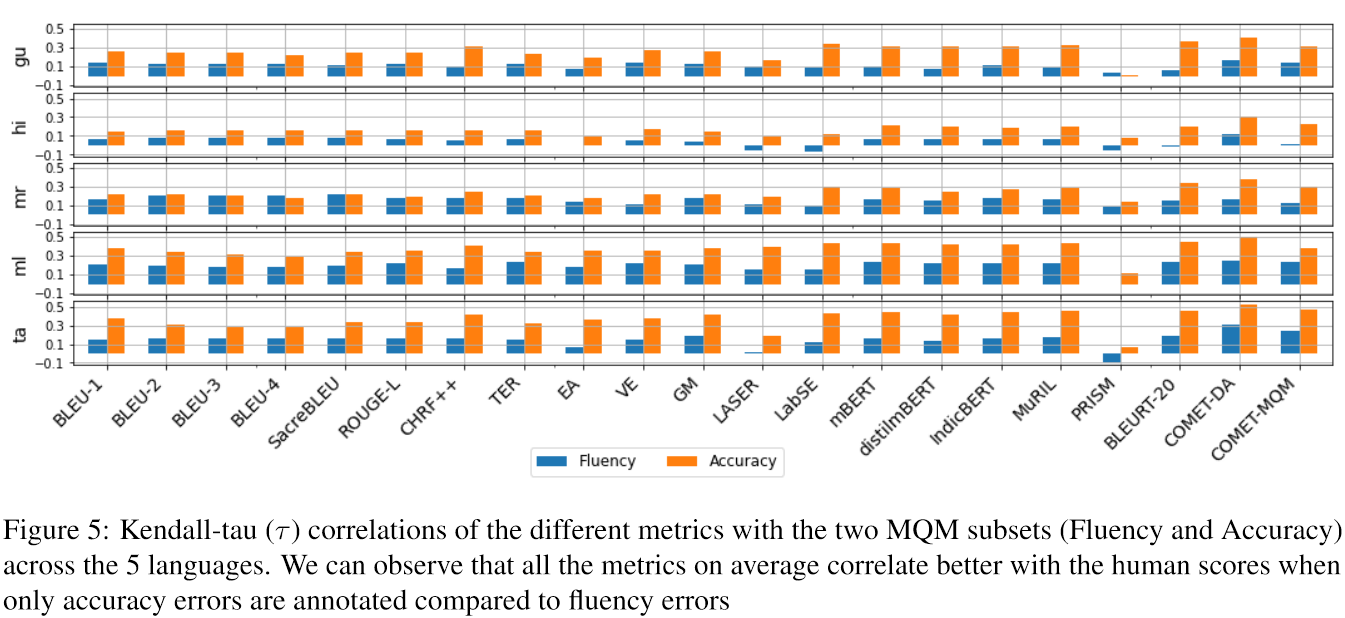
For instance, the chrF++ metric showed the highest correlation among overlap-based metrics across all languages, while embedding-based metrics like LabSE embeddings yielded better correlations than other metrics. Surprisingly, PRISM, trained on multiple languages, did not perform well, which could be attributed to its minimal training on Indian languages.
System-Level Evaluation: Do the Metrics' Ranking of MT systems Match the Human Rankings?
While operating at the system level, all the metrics perform reasonably well compared to their performance at the sentence-level, aka segment-level. A startling revelation was the effectiveness of Indic-COMET, an adaptation of the COMET metric, which outperformed even when tested on unseen Indian languages, when trained on other Indian languages
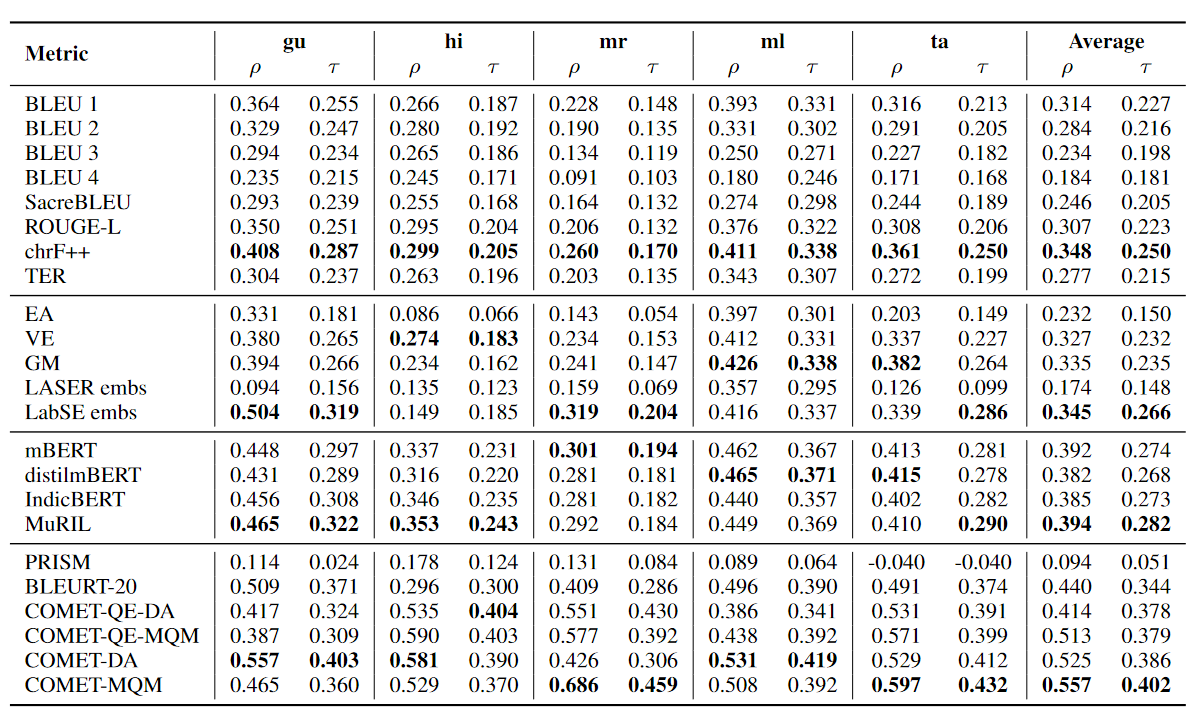
System-level Pearson (ρ) and Kendall-tau (τ ) correlations of different metrics. The best performing metric
in each category in bold. (∗) signifies that the correlation value is significant (p < 0.05).
This finding is a testament to the importance of incorporating language-specific nuances in the training of MT metrics.
Conclusions and Future Directions
The “IndicMT Eval” study not only highlights the discrepancies in MT metric performance for Indian languages but also sets a precedent for future research. It urges the MT community to focus on creating and refining metrics that are inclusive of linguistic diversity.
The positive impact of Indic-COMET on unseen languages suggests a promising direction for advancing MT evaluation metrics – by focusing on a subset of languages, we can create ripple effects on related languages that can benefit a wider linguistic landscape.
Final Thoughts
The “IndicMT Eval” study is a clarion call for the MT community to reassess and innovate the evaluation metrics we rely on. As machine translation becomes increasingly integral to global communication, ensuring that all languages are represented and accurately evaluated in MT systems is not just a technical necessity but also a cultural imperative.
"Translation is not just about converting words; it's a bridge that connects cultures. IndicMT Eval strives to build a stronger bridge, ensuring that the journey from one language to another is not just accurate but resonates with the richness and nuances of each linguistic tapestry."