
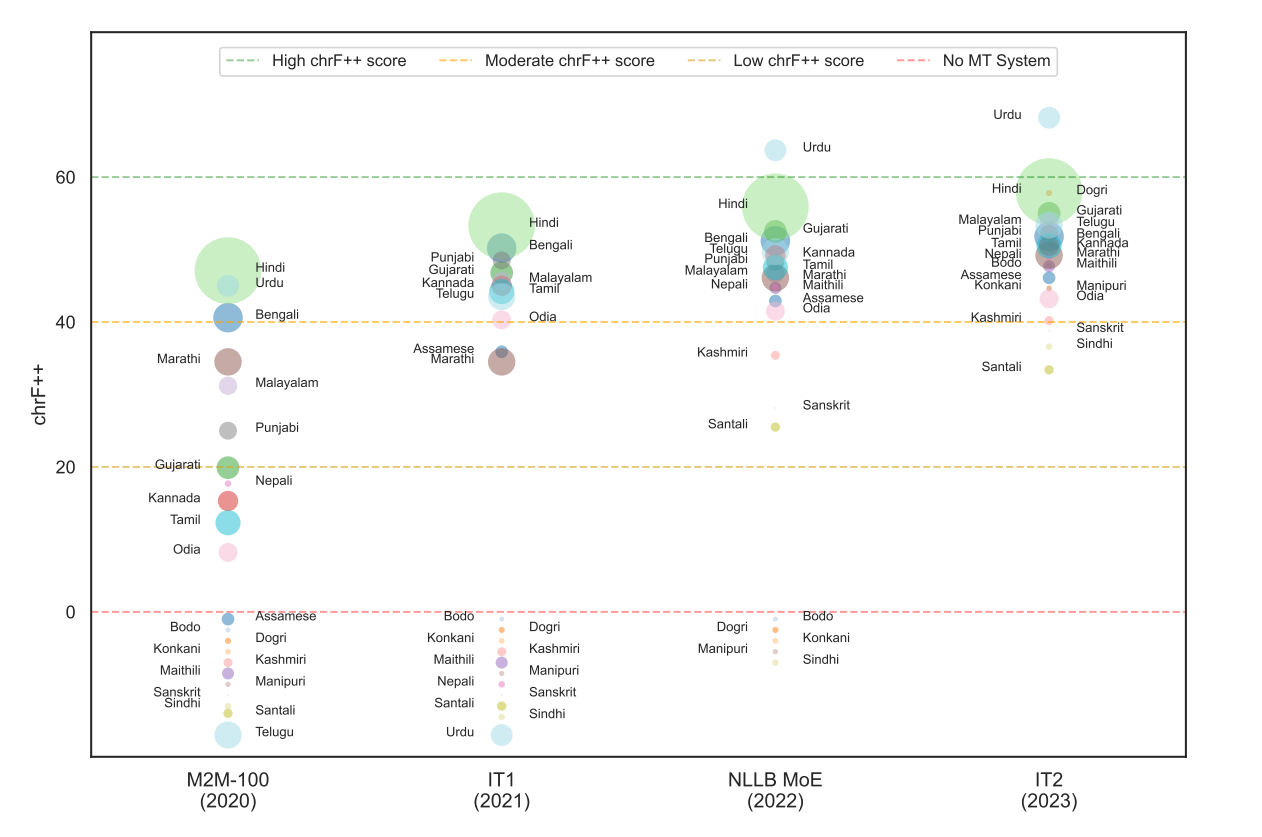
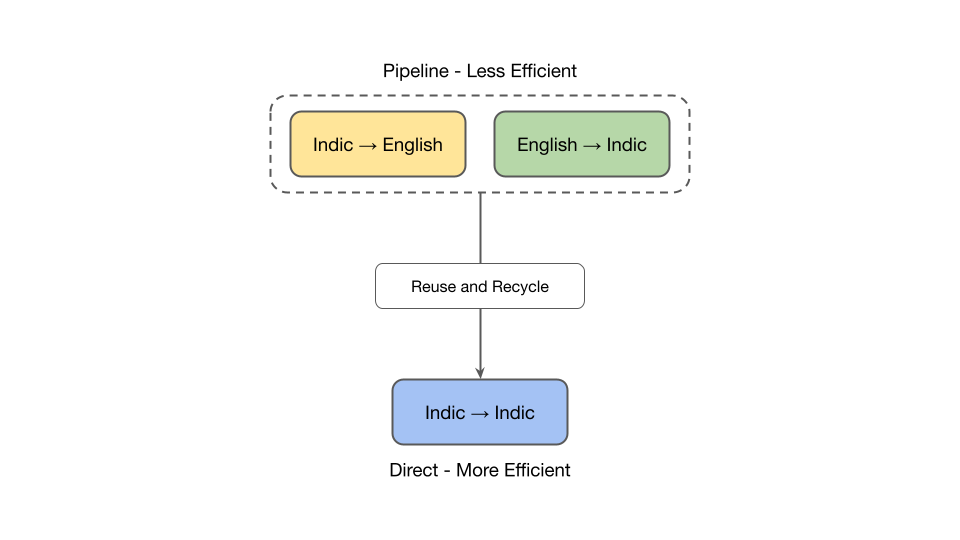
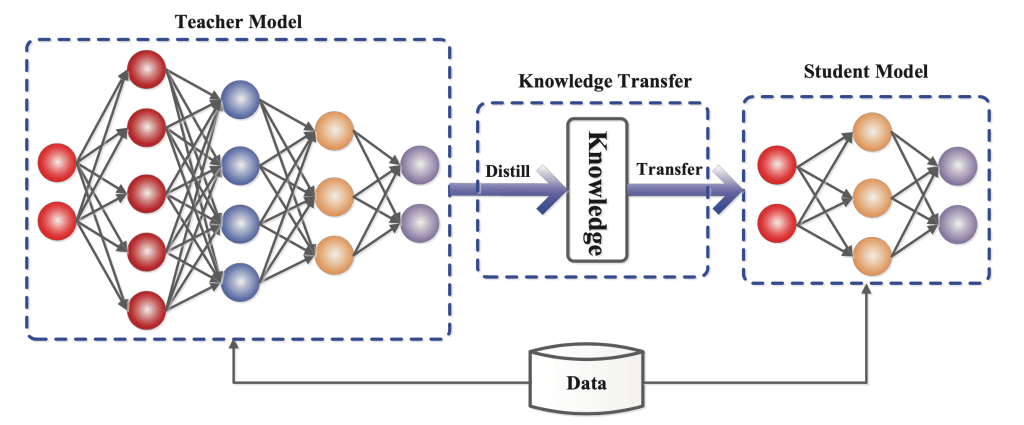
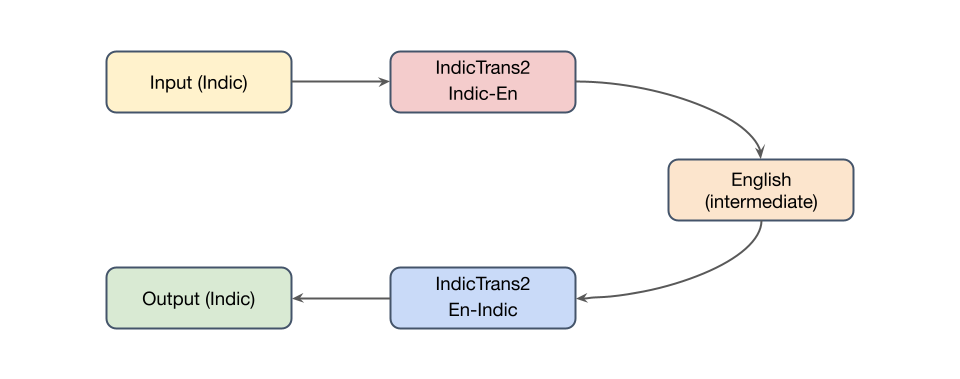
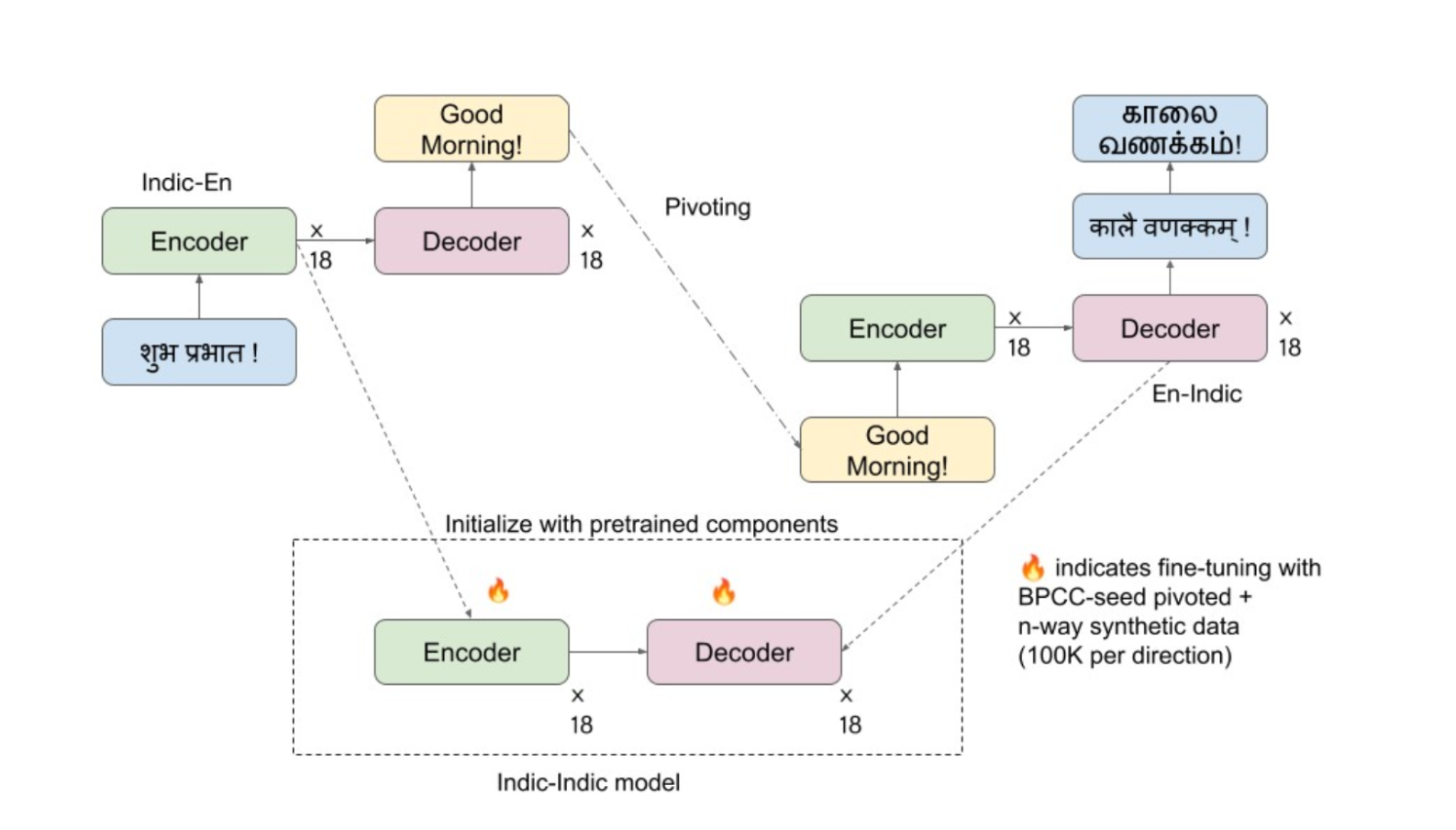
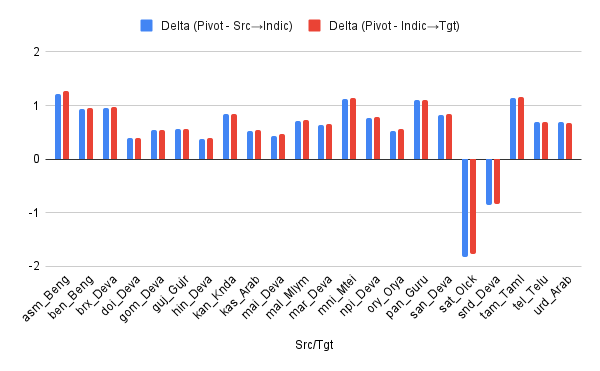
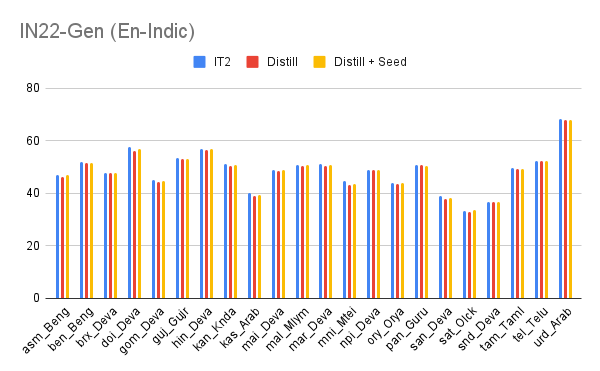
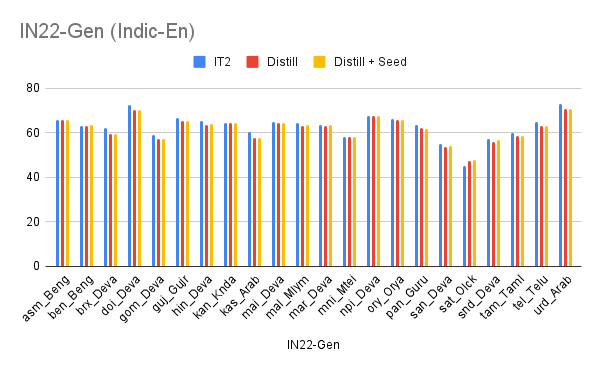
We officially release on HuggingFace  our IndicTrans2-M2M model, its compact variant as well as the compact versions of the original English centric IndicTrans2 models (Indic-English and English-Indic). Our models are released with a MIT license and can be used for both research and commercial purposes. Kindly feel free to try them out and use them in your applications. For technical details, check out IndicTrans2 paper (now accepted to TMLR) and its GitHub repo. Feedback is always appreciated.
our IndicTrans2-M2M model, its compact variant as well as the compact versions of the original English centric IndicTrans2 models (Indic-English and English-Indic). Our models are released with a MIT license and can be used for both research and commercial purposes. Kindly feel free to try them out and use them in your applications. For technical details, check out IndicTrans2 paper (now accepted to TMLR) and its GitHub repo. Feedback is always appreciated.